前端架构
前端路由
什么是前端路由?
前端路由就是把不同路由对应不同的内容或页面的任务交给前端来做,之前是通过服务端根据 url 的不同返回不同的页面实现的。
什么时候使用前端路由?
在单页面应用,大部分页面结构不变,只改变部分内容的使用
前端路由有什么优点和缺点?
优点:用户体验好,不需要每次都从服务器全部获取,快速展现给用户。
缺点:单页面无法记住之前滚动的位置,无法在前进,后退的时候记住滚动的位置。
前端路由一共有两种实现方式,一种是通过 hash 的方式,一种是通过使用 pushState 的方 式。
实现一个页面操作不会整页刷新的网站,并且能在浏览器前进、后退时正确响应。给出你的技术实现方案
- 利用 location.hash 来实现
hash 属性是Javascript原生的属性,是一个可读写的字符串,该字符串是 URL 的锚部分(从 # 号开始的部分)。比如 location.href = "http://blog.chenxu.me/post/#1",那么 location.hash = "#1"。通过设置 hash 可以操作浏览器的历史记录(即前进、后退)。
2、利用 history.pushState API
pushState 是 Html5 中引入的新特性,用来修改浏览器的历史记录。通过 pushState 把记录保存到浏览器的历史数据中,然后通过windows.onpopstate事件来响应浏览器的前进、后退操作。
通过使用 pushState + ajax 实现浏览器无刷新前进后退,当一次 ajax 调用成功后我们将一 条 state 记录加入到 history对象中。一条 state 记录包含了 url、title 和 content 属性,在 popstate 事件中可以 获取到这个 state 对象,我们可以使用 content 来传递数据。最后我们通过对 window.onpopstate 事件监听来响应浏览器 的前进后退操作。
使用 pushState 来实现有两个问题,一个是打开首页时没有记录,我们可以使用 replaceState 来将首页的记录替换,另一个问题是当一个页面刷新的时候,仍然会向服务器端请求数据,因此如果请求的 url 需要后端的配 合将其重定向到一个页面。
参考:
pushState + ajax 实现浏览器无刷新前进后退 - Charley Blog
window.open打开页面会被浏览器拦截问题解决
window.open是 javascript 函数,该函数的作用是打开一个新窗口或改变原窗口, 如果你直接在 js 中调用window.open()去打开一个新窗口,浏览器会拦截。 (注意:window.open(url,'_self')在原窗口打开,不会被拦截)。
普通情况下 window.open 不会拦截,但若是在 ajax 的回调里面进行 window.open,会拦截!因为浏览器会认为这是一个骚扰用户的行为。 在网上找到一些解决方案,总结如下。其中只有方案 1、方案 2 个人验证过有效。其他未知 orz...
方案 1: 先 window.open('_blank'),再赋值 location 跳转链接
var tempWin = window.open("_blank");
$.ajax({
type: "post",
url: xxx,
data: data,
contentType: "application/json;charset=UTF-8",
success: function (response) {
tempWin.kk = "www.baidu.com";
}
});
这种情况有个缺陷:
- 若你的新页面需要从 sessionStorage 取值,那这种方式是取不到的。 **解决方法:**采用 url 传参方式。比如
tempWin.kk = "www.baidu.com?id=xxxx";. 然后通过以下getParam方法获取 url 参数:
function getParam(a) {
var b = new RegExp("(^|&)" + a + "=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(b);
if (r != null) return unescape(r[2]);
return ""
}
- 若你在 ajax 请求成功后还有业务判断,判断后决定是否要跳转。这时候预先打开一个空页签就很鸡肋。 解决方法:参考网上方案,只能采用方案 2
方案 2:设置 ajax 请求为async:false——同步模式。
$.ajax({
type: "post",
url: "/xxxx/xxxx",
async: false,
data: data,
contentType: "application/json;charset=UTF-8",
success: function (data) {
if(xxx){
window.open(url);
}
}
});
异步当然有异步的好处,全部同步那就呵呵哒了,所以局部使用吧。
(接下来的方案,各自看看试试,不保证管用,只是搜集来 mark 下)
方案 3:采用 a 标签
<a href="" target="_blank">click me</a>
# 点击这个超链接,浏览器会认为它是打开一个新的链接,就不会拦截。
<a href="javascript:void(0)" onclick="window.open()"></a>
缺陷:有时候需要点击时候,进行一些其他设置或操作,再跳转。所以需要在 js 中完成。
方案 4:笨笨的 setTimeout
使用 setTimeout 包装一下,也可以防止被浏览器拦截。注意这里的超时时间不能太短,否则也会被拦截。
setTimeout('window.open(url);', 500);
方案 5:创建 form 标签,js 代码进行提交
创建一个 form 新元素,并赋予响应属性,然后手动代码进行 submit(); 注意:若需传递参数?id=1类似这种,需要指定 POST 方法。默认是 GET 方法,无法传递参数。
var form = document.createElement('form');
form.action = 'www.baidu.com?id=1';
form.target = '_blank';
form.method = 'POST';
document.body.appendChild(form);
form.submit();
方案 6:巧用 a 标签的特性:创建一个 a 标签,手动代码进行 click 触发。
function newWin(url, id) {
var a = document.createElement('a');
a.setAttribute('href', url);
a.setAttribute('target', '_blank');
a.setAttribute('id', id);
if(!document.getElementById(id)) {
document.body.appendChild(a);
}
a.click();
}
参考:
window.open打开页面会被浏览器拦截问题解决 - 云+社区 - 腾讯云
数据状态管理
前端常见数据状态管理方案有哪些?它们各有什么优缺点?
目前优秀的状态管理库有Vuex、Flux、Redux、MobX等等。所有的状态管理要做的事情,最核心的是:
把组件之间需要共享的状态抽取出来,遵循特定的约定,统一来管理,让状态的变化可以预测。
Flux
Flux是一种思想,所有库都可以根据这种思想来做自己的实现。 Flux有四个关键概念:View、Action、Dispatcher、Store

View即展示层,比如Vue组件或者React组件。
Store就是Vue展示所需要的数据,存储的地方。可以把Store都放在一起,也可以分开放。Store改变后,View需要对应改变(这里不同的库可以有自己不同的实现方式)
View如果要通过用户操作或其他交互形式,改变Store的话,必须要经过Dispatcher来Dispatch一个action。Dispatcher的作用就是接收所有的Action,并分发给所有的Store。
Redux
Redux在Flux思想的基础上,做了自己的实现。

Redux中只有一个Store,这个Store里的State变化了后,View层自动渲染。
Store 允许使用 store.subscribe 方法设置监听函数,一旦 State 发生变化,就自动执行这个函数。这样不管 View 是用什么实现的,只要把 View 的更新函数 subscribe 一下,就可以实现 State 变化之后,View 自动渲染了。比如在 React 里,把组件的render方法或setState方法订阅进去就行。
Action的就是View发出的通知,Action必须有type属性,代表其名称。
Reducer类似于Dispatcher,Reducer 是一个纯函数,对于相同的输入,永远都只会有相同的输出。Redux 有很多的 Reducer,对于大型应用来说,State 必然十分庞大,导致 Reducer 函数也十分庞大,所以需要做拆分。Redux 里每一个 Reducer 负责维护 State 树里面的一部分数据,多个 Reducer 可以通过 combineReducers 方法合成一个根 Reducer,这个根 Reducer 负责维护整个 State。
Redux和Flux在都是单向数据流的基础上,有以下几点区别:
- Redux单一数据源,而Flux允许多个数据源;
- Redux的state是只读的,Flux的state可以随便改;
- Redux的Reducer一定是纯函数,而Flux的Action不一定
另外Redux中存在一个中间件的概念。在Action到Reducer的过程中,给Reducer包装了一层。

中间件可以用过做日志分析,也可以做异步处理,等等。用 Redux 处理异步,可以自己写中间件来处理,当然大多数人会选择一些现成的支持异步处理的中间件。比如 redux-thunk 或 redux-promise。
Vuex
Vuex主要是和Vue绑定的,思想类似于Redux和Flux。
主要概念是Action、Mutations和Store。

每一个Vuex里有一个全局的Store,包含应用中的状态State。Vuex将state植入了整个应用,挂载在Vue的原型上,方便通过this.$store直接取用。
State改变后,View层也会随之改动。
Mutations类似于Redux的Reducer,必须是同步的。但是Vuex不要求每次搞一个新的state,而是可以直接修改state,这一点又和Flux类似。
Action就好比Reducer的中间件,可以用来处理异步。
MobX
MobX的理念是状态变化后,其他用到状态的地方就自动变化。

Redux更多的是遵循函数式编程(Functional Programming, FP)思想,而Mobx则更多从面相对象角度考虑问题。
store是应用管理数据的地方,在Redux应用中,我们总是将所有共享的应用数据集中在一个大的store中,而Mobx则通常按模块将应用状态划分,在多个独立的store中管理。
基于以上区别,我们可以简单得分析一下两者的不同使用场景.
mobx更适合数据不复杂的应用: mobx难以调试,很多状态无法回溯,面对复杂度高的应用时,往往力不从心. redux适合有回溯需求的应用: 比如一个画板应用、一个表格应用,很多时候需要撤销、重做等操作,由于redux不可变的特性,天然支持这些操作.
mobx适合短平快的项目: mobx上手简单,样板代码少,可以很大程度上提高开发效率.
当然mobx和redux也并不一定是非此即彼的关系,你也可以在项目中用redux作为全局状态管理,用mobx作为组件局部状态管理器来用.
参考:
为什么在React中使用Redux需要用到React-redux?这个到底是做什么的?
首先了解Redux和Flux类似,只是一种思想和规范,它和React之间没有任何关系。Redux可以直接各种库,甚至是Fultter、Dart。
React-redux是React官方出品的,处理Redux和React UI的绑定。
React的组件化思路中,有容器组件和展示组件的区分:

react-redux 就是多了个 connect 方法连接容器组件和UI组件,这里的“连接”就是一种映射:
mapStateToProps 把容器组件的 state 映射到UI组件的 props
mapDispatchToProps 把UI组件的事件映射到 dispatch 方法
权限一般怎么管理?
以vue为例。一般思路是通过获取当前用户的权限去比对路由表,生成当前用户具有的权限可访问的路由表,通过 router.addRoutes 动态挂载到 router 上。
或者封装成指令vue-element-admin/permission.js at master · PanJiaChen/vue-element-admin,来精细化控制:
<template>
<!-- Admin can see this -->
<el-tag v-permission="['admin']">admin</el-tag>
<!-- Editor can see this -->
<el-tag v-permission="['editor']">editor</el-tag>
<!-- Editor can see this -->
<el-tag v-permission="['admin','editor']">Both admin or editor can see this</el-tag>
</template>
<script>
// 当然你也可以为了方便使用,将它注册到全局
import permission from '@/directive/permission/index.js' // 权限判断指令
export default{
directives: { permission }
}
</script>
获取权限判断函数:
<template>
<el-tab-pane v-if="checkPermission(['admin'])" label="Admin">Admin can see this</el-tab-pane>
<el-tab-pane v-if="checkPermission(['editor'])" label="Editor">Editor can see this</el-tab-pane>
<el-tab-pane v-if="checkPermission(['admin','editor'])" label="Admin-OR-Editor">Both admin or editor can see this</el-tab-pane>
</template>
<script>
import checkPermission from '@/utils/permission' // 权限判断函数
export default{
methods: {
checkPermission
}
}
</script>
参考:
immutable、immer这种对象不可变的库是做什么的?他怎么做的?
用来改变深层次对象时降低性能损耗的。
immutablejs创建的对象无法更改,通过结构共享,每次修改只会影响当前节点其他节点不会改变,通过这种方式产生新的immutablejs对象,避免性能损耗:
const { fromJS } = require('immutable')
const data = {
content: {
time: '2018-02-01',
val: 'Hello World',
},
desc: {
text: 'a',
},
}
// 把 data 转化为 immutable-js 中的内置对象
const a = fromJS(data)
const b = a.setIn(['desc', 'text'], 'b')
console.log(b.get('desc') === a.get('desc')) // false
// content 的值没有改动过,所以 a 和 b 的 content 还保持着引用
console.log(b.get('content') === a.get('content')) // true
// 将 immutable-js 的内置对象又转化为 JS 原生的内容
const c = a.toJS()
const d = b.toJS()
// 这时我们发现所有的引用都断开了
console.log(c.desc === d.desc) // false
console.log(c.content === d.content) // false
immer 的作者同时也是 mobx 的作者。mobx 又像是把 Vue 的一套东西融合进了 React,已经在社区取得了不错的反响。immer 则是他在 immutable 方面所做的另一个实践。 与 immutable-js 最大的不同,immer 是使用原生数据结构的 API 而不是像 immutable-js 那样转化为内置对象之后使用内置的 API,举个简单例子:
const produce = require('immer')
const state = {
done: false,
val: 'string',
}
// 所有具有副作用的操作,都可以放入 produce 函数的第二个参数内进行
// 最终返回的结果并不影响原来的数据
const newState = produce(state, (draft) => {
draft.done = true
})
console.log(state.done) // false
console.log(newState.done) // true
参考:
immer.js:也许更适合你的immutable js库 - 掘金
immer的原理是什么?
Immer 源码中,使用了一个 ES6 的新特性 Proxy 对象。Proxy 对象允许拦截某些操作并实现自定义行为。
immer 的做法就是维护一份 state 在内部,劫持所有操作,内部来判断是否有变化从而最终决定如何返回。
参考:
immer.js:也许更适合你的immutable js库 - 掘金
数据收集
前端数据埋点时,为什么使用1*1像素的透明gif图片而不是接口?
埋点接口的实现是,请求一个gif图的方式,带上埋点的数据。
为什么用图片不用接口或者js、css,是因为:
- 没有跨域问题
- 不会阻塞页面的加载
- 不会改dom。只要在js中new出Image对象就能发起请求
- 在没有js的浏览器环境中也能通过img标签正常打点,这是其他类型的资源请求所做不到的。
为什么用gif,是因为: GIF的最低合法体积最小(最小的BMP文件需要74个字节,PNG需要67个字节,而合法的GIF,只需要43个字节)
至于信息,可以用encode后放在url上给后端解析。
参考:
前端埋点打点系统相关设计
整体流程:
1、写一段 js 脚本,前端通过 script 标签引入这段 js; 2、通过页面的用户行为,触发相应 js 事件,并拿到数据; 3、通过请求 nginx 上某一个静态资源的形式,将数据进行拼接发送到 nginx; 4、nginx 产生一条日志,云端拿到数据进行清洗、分析。
关于js上报部分3中方式实现埋点:
1、代码埋点
代码埋点需要开发者在埋点的节点处插入埋点代码,例如点击事件的回调、元素的展示回调方法、页面的生命周期函数等等。业务场景不能通过 dom 代码埋点方式获取,js 为此提供了 track 方法,并挂在 window 上,供开发者调用。
2、可视化圈选埋点
通俗的讲就是无需开发者在代码中加入埋点逻辑代码,只需要通过 UI 点点点的方式就能埋好一个点,有效避免了埋点代码污染问题。被点击到的 dom 元素都赋予唯一标识,这里采用 dom 元素唯一的 xpath 当作唯一标识。
说白了,可视化圈选埋点就是制定一套规则,云端利用这套规则去海量的数据里清洗出需要的数据,而规则中就包含了 xpath。
3、无痕埋点
无痕埋点也叫 “全埋点”,有了以上两种方式埋点,无痕埋点自然也就简单了,点击到任何 dom 时都进行上报,然后再获取 dom 的 xpath 作为唯一标识,就可以轻松实现全埋点上报了,剩下的就交给数仓获取、清洗数据吧
关于云端如何采集数据:
数据采集分为 实时数据 和 离线数据。
实时数据 采集的数据流向的两种方式,主要经历的过程是:
第一种方式:目前应用场景主要是客户端实时校验。nginx 日志通过 filebeat 收集统一上报到 日志kafka,日志kafka 会接收到来自很多其它应用的日志数据,所以通过 flink 过滤出哪些数据是需要的数据(埋点数据)再上报到 数据kafka ,然后 Java应用 去消费这些数据,通过 websocket 把这些实时数据给 web 端。
第二种方式:主要是提供各种应用容器日志的数据查询,也就是 ELK 模型。nginx 日志通过 logstash 收集,logstash 和 filebeat 同样都可以做数据收集,它们的区别主要是,filebeat 是一个轻量型日志采集器,主要的能力是数据 收集;而 logstash 更多的能力是体现在数据的过滤和转换上。logstash 收集到数据后,将数据统一往 ES 中存,然后在 kibana 中建一个索引就可以看数据啦。
参考:
SEO
有哪些需要注意的SEO的点?
合理的title、description、keywords:搜索对着三项的权重逐个减小,title值强调重点即可;description把页面内容高度概括,不可过分堆砌关键词;keywords列举出重要关键词。
语义化的HTML代码,符合W3C规范:语义化代码让搜索引擎容易理解网页
重要内容HTML代码放在最前:搜索引擎抓取HTML顺序是从上到下,保证重要内容一定会被抓取
重要内容不要用js输出:爬虫不会执行js获取内容
少用iframe:搜索引擎不会抓取iframe中的内容
非装饰性图片必须加alt
提高网站速度:网站速度是搜索引擎排序的一个重要指标
前后端分离的项目使用服务端同构渲染,既提高了访问速度,同时重要关键内容首次渲染不通过 js 输出
友情链接,好的友情链接可以快速的提高你的网站权重
外链,高质量的外链,会给你的网站提高源源不断的权重提升
向各大搜索引擎登陆入口提交尚未收录站点
SPA如果不做SSR,如何做SEO?
先去 www.baidu.com/robots.txt 找出常见的爬虫,然后在nginx上判断来访问页面用户的User-Agent是否是爬虫,如果是爬虫,就用nginx方向代理到我们自己用nodejs + puppeteer实现的爬虫服务器上,然后用你的爬虫服务器爬自己的前后端分离的前端项目页面,增加扒页面的接收延时,保证异步渲染的接口数据返回,最后得到了页面的数据,返还给来访问的爬虫即可。
参考地址:
通信相关
跨浏览器Tab通信有哪些解决方案?
- window.open配合句柄postmessage
缺点是只能与自己打开的页面完成通讯,应用面相对较窄;但优点是在跨域场景中依然可以使用该方案。
// parent.html
const childPage = window.open('child.html', 'child')
childPage.onload = () => {
childPage.postMessage('hello', location.origin)
}
// child.html
window.onmessage = evt => {
// evt.data
}
- localStorage
API简单直观,兼容性好,除了跨域场景下需要配合其他方案(如iframe跨域postmessage),无其他缺点
// A.html
localStorage.setItem('message', 'hello')
// B.html
window.onstorage = evt => {
// evt.key, evt.oldValue, evt.newValue
}
- BroadcastChannel
和localStorage方案没特别区别,都是同域、API简单,BroadcastChannel方案兼容性差些(chrome > 58),但比localStorage方案生命周期短(不会持久化),相对干净些。
// A.html
const channel = new BroadcastChannel('tabs')
channel.onmessage = evt => {
// evt.data
}
// B.html
const channel = new BroadcastChannel('tabs')
channel.postMessage('hello')
- SharedWorker
SharedWorker本身并不是为了解决通讯需求的,它的设计初衷应该是类似总控,将一些通用逻辑放在SharedWorker中处理。不过因为也能实现通讯。相较于其他方案没有优势,此外,API复杂而且调试不方便。
// A.html
var sharedworker = new SharedWorker('worker.js')
sharedworker.port.start()
sharedworker.port.onmessage = evt => {
// evt.data
}
// B.html
var sharedworker = new SharedWorker('worker.js')
sharedworker.port.start()
sharedworker.port.postMessage('hello')
// worker.js
const ports = []
onconnect = e => {
const port = e.ports[0]
ports.push(port)
port.onmessage = evt => {
ports.filter(v => v!== port) // 此处为了贴近其他方案的实现,剔除自己
.forEach(p => p.postMessage(evt.data))
}
}
- 服务端支持
socket、cookie等等
参考:
前端如何实时获取版本更新信息从而提示用户?
- 使用WebSocket, 当发布的时候推送到前端,前端收到通知进行更新操作
- 前端设计一套算法, 不定时地去服务端询问有没有最新的版本,有的话则进行更新
这里有几个点:
1、我们可以直接让后端写一个接口
2、我们写一个node层做这个事情,毕竟这个逻辑后端不care.
3、我们可以直接将当前最新版本的信息放到CDN中,然后将更新最新版本信息的功能加入到构建中。 比如我们静态资源访问路径为: cdn.lucifer.ren/pageA/index.html, 我们可以把这个文件放到 cdn.lucifer.ren/pageA/manifest.json
{
version : '1.0.2'
}
我们访问这个路径,解析JSON,拿到version字段,通过和本地的version比较,本地version记录方法就很多了, 可以加入构建,也可以放到url中。 关于这个算法,大家可以发挥自己的脑洞。我这里想了一个。 就是根据用户的交互信息和时间来设计一个延迟查询。 如果用户发生了交互行为,比如点击,我就会延迟n秒发送一个查询。如果用户没有任何交互,我就不发送。 当然这个n是可变的,并且如果用户交互比较频繁,也要做一个截流的功能, 比如60秒只会发送一次。
参考:
Websocket相比http有什么优势?
客户端与服务器只需要一个TCP连接,比http长轮询使用更少的连接
webSocket服务端可以推送数据到客户端
更轻量的协议头,减少数据传输量
参考:
Node.js 有难度的面试题,你能答对几个? - 云+社区 - 腾讯云
请求资源的时候不要让它带 cookie 怎么做?
网站向服务器请求的时候,会自动带上 cookie 这样增加表头信息量,使请求变慢。
如果静态文件都放在主域名下,那静态文件请求的时候都带有的 cookie 的数据提交给 server 的,非常浪费流量,所以不如隔离开 ,静态资源放 CDN。
因为 cookie 有域的限制,因此不能跨域提交请求,故使用非主要域名的时候,请求头中就 不会带有 cookie 数据,这样可以降低请 求头的大小,降低请求时间,从而达到降低整体请求延时的目的。
同时这种方式不会将 cookie 传入 WebServer,也减少了 WebServer 对 cookie 的处理分析环节, 提高了 webserver 的 http 请求的解析速度。
一个接口在什么情况下会cancel,怎么解决?
1、手动通过js取消比如AbortController,或者promise.race失败,或者配合路由钩子来手动cancel,防止SPA切换后接口继续发。
2、接口还没有发出去,页面就跳转了或者刷新了。解决方案是改为同步接口。
3、表单提交submit时部分浏览器会刷新页面(即使看不出来),也会触发刷新流程,偶现cancel。解决方案是submit时event.preventDefault()
参考:
vue路由切换时取消上个页面的异步请求_zmmfjy的博客-CSDN博客
性能优化
首屏和白屏时间怎么定义?如何计算?
白屏时间:从浏览器输入地址并回车后到页面开始有内容的时间;
首屏时间:从浏览器输入地址并回车后到首屏内容渲染完毕的时间;
白屏时间节点指的是从用户进入网站(输入url、刷新、跳转等方式)的时刻开始计算,一直到页面有内容展示出来的时间节点。 这个过程包括dns查询、建立tcp连接、发送首个http请求(如果使用https还要介入TLS的验证时间)、返回html文档、html文档head解析完毕。
首屏时间 = 白屏时间 + 首屏渲染时间
通过window.performance来计算。
具体的逻辑实现可以参考我写的brizer/web-monitor-sdk: SDK for web monitor, a simple web data collection tool for performance, exceptions, etc.
白屏时间计算
将代码脚本放在 </head> 前面就能获取白屏时间:
new Date().getTime() - performance.timing.navigationStart
首屏时间计算
在window.onload事件中执行以下代码,可以获取首屏时间:
new Date().getTime() - performance.timing.navigationStart
参考:
首屏性能优化
- 做cdn 升级http2.0
- 开启http缓存
- 减少资源体积:开启gzip压缩(Nginx或webpack打包均可做);Chrome的coverage分析代码,剔除首屏不需要的代码,可使用splitChunksPlugin打成一个个包
- 优化渲染路径,将js放在body后。做ssr服务端渲染
- 图片懒加载
无限滚动列表
首先了解如何判断dom在视窗范围内? 1.保证DOM数量不会溢出
元素太多会影响页面性能,主要原因有两重:一是浏览器占用内存过多(1000张 50KB 的图片需要50MB 内存,10000张就会占用 0.5GB 内存,足以让 Chrome 崩溃);我们认为没有必要一次性把所有的图片都加载进页面,而是监听用户对页面的操作,当滚动页面时,再显示出对应位置上的图片。 有些图片虽然之前可见,但现在由于页面滚动,已经被移出了视口,那就把它们拿出来。 即使用户已经在页面上浏览过成百上千张照片,但由于视口的限制,每次需要渲染的图片却都不会超过50张。这样的策略下,用户的交互总能得到及时的响应,浏览器也不容易发生崩溃。
2.数据的懒加载以及进一步判断速度决定图片质量
首先要检查页面滚动方向,要预加载的是用户即将看到的内容;还会根据用户滚动页面的速度识别是否要加载高清原图,如果发现用户只是在飞速地浏览图片,那加载原图也就没有必要了;甚至当页面滚动速度快到一定程度,连低分辨率的占位图都不用加载了。 无论加载的是原图还是低分辨率的占位图,都会有缩放图片的场景。现在的显示屏基本都是高清屏,常见的做法是加载一张两倍于占位尺寸大小的图片,然后缩小一半放到对应位置上(这样做,实际一个像素就能承载两倍的信息量)。对于低分辨占位图来说,我们可以请求非常小且压缩率很高(比如压缩率75%)的资源,然后放大它们。
3.不定高的item怎么办?
一般的列表item是定高,所以计算起来比较方便,如果是不定高的场景,应该怎么办呢?
有两种方式:
第一个是将当前元素先在屏外进行绘制,并对齐高度进行测量后,再将其渲染到用户可视区域内。 比如说在底部先渲染了拿到了高度,再去计算;
第二个是item已经渲染,但是通过mutationObserver拿到改变后的高度,再去参与计算。
参考:
见微知著,Google Photos Web UI 完善之旅 - 知乎
大量 DOM 操作,应该如何优化?
最简单的,使用 document,fragment
var fragment = document.createDocumentFragment();
fragment.appendChild(elem);
如果是需要 diff,比对替换,则需要 Virtualdom;如果还是遇到性能瓶颈,则需要类似 React 的 Fiber 一样,通过 requestIdleCallback 和 requestAnimationFrame 来进一步通过任务调度的方式来优化。
浏览器端大数据问题,两万个小球记住信息,进行最优检索和存储?
如果你仅仅只是答用数组对象存储了 2 万个小球信息,然后用 for 循环去遍历进行索引,那是远远不够的。
这题要往深一点走,用特殊的数据结构和算法进行存储和索引。
然后进行存储和速度的一个权衡和对比,最终给出你认为的最优解。
我提供几个思路:
用 ArrayBuffer 实现极致存储
哈夫曼编码 + 字典查询树实现更优索引
用 bit-map 实现大数据筛查
用 hash 索引实现简单快捷的检索
用 IndexedDB 实现动态存储扩充浏览器端虚拟容量
用 iframe 的漏洞实现浏览器端 localStorage 无限存储,实现 2 千万小球信息存储
两万个小球,做流畅的动画效果?
这题考察对大数据的动画显示优化,当然方法有很多种。
但是你有没有用到浏览器的高级 api?
你还有没有用到浏览器的专门针对动画的引擎?
或者你对 3D 的实践和优化,都可以给面试官展示出来。
提供几个思路:
使用 GPU 硬件加速
使用 webGL
使用 assembly 辅助计算,然后在浏览器端控制动画帧频
用 web worker 实现 javascript 多线程,分块处理小球
用单链表树算法和携程机制,实现任务动态分割和任务暂停、恢复、回滚,动态渲染和处理小球
了解 SPA 的懒加载么?(todo)
图片的懒加载和预加载怎么做?
懒加载也叫延迟加载,指的是在长网页中延迟加载图片的时机,当用户需要访问时,再去加载, 这样可以提高网站的首屏加载速度,提升用户的体验,并且可以减少服务器的压力。它适用于图 片很多,页面很长的电商网站的场景。懒加载的实现原理是,将页面上的图片的 src 属性设置 为空字符串,将图片的真实路径保存在一个自定义属性中,当页面滚动的时候,进行判断,如果 图片进入页面可视区域内,则从自定义属性中取出真实路径赋值给图片的 src 属性,以此来实 现图片的延迟加载。
预加载指的是将所需的资源提前请求加载到本地,这样后面在需要用到时就直接从缓存取资源。 通过预加载能够减少用户的等待时间,提高用户的体验。我了解的预加载的最常用的方式是使用 js 中的 image 对象,通过为 image 对象来设置 src 属性,来实现图片的预加载。
这两种方式都是提高网页性能的方式,两者主要区别是一个是提前加载,一个是迟缓甚至不加载。 懒加载对服务器前端有一定的缓解压力作用,预加载则会增加服务器前端压力。
图片预加载的实现可以参考FunnyLiu/preloader at readsource以及@tomato-js我的实现。
参考:
做过哪些提高页面加载的性能优化点?
1、优化网络等硬件条件
1.1、最小化和压缩网络请求。参考Minify and compress network payloads
代码压缩。
数据压缩(gzip、甚至是Brotli)
1.2 使用cdn。参考Use image CDNs to optimize images
具体可以了解:谈谈cdn服务
1.3、增加dns预加载。
<link rel="preconnect" href="http://example.com">
<link rel="dns-prefetch" href="http://example.com">
2、优化js的执行
2.1、通过代码拆分减少JavaScript负载;参考Reduce JavaScript payloads with code splitting
路由分隔,基于codesplit,路由或者组件逻辑分隔。
2.2、 使用PRPL模式(Push(或预加载)最重要的资源。参考Apply instant loading with the PRPL pattern
尽快Render初始路线。Pre-cache剩余资产。Lazyload其他路由和非关键资产。)应用即时加载。
给样式增加preload:<link rel="preload" as="style" href="css/style.css">
对不做dom操作的js资源做async异步加载优化。
服务端渲染页面。
使用serviceworker的precache来缓存不变的静态资源。这不仅使用户可以在脱机时使用您的应用程序,而且还可以缩短重复访问时的页面加载时间。
懒加载图片和js。
2.3 删除未使用的代码。参考Remove unused code
利用chrome的coverage或者webpack的BundleAnalyzerPlugin来分析依赖使用率。然后进行业务改造。
2.4 缩小和压缩网络负载。参考Minify and compress network payloads
文件大小压缩。数据gzip压缩。
2.5 将现代代码提供给现代浏览器,以加快页面加载速度。参考Serve modern code to modern browsers for faster page loads
使用babel/preset-env指定需要兼容的浏览器。
使用esm,也就是<script type="module">。
使用现代的库,esm,新语法、treeshaking等等来提高性能。
2.6 优化用户交互逻辑
在最快的情况下,当用户与页面交互时,页面的合成器线程可以获取用户的触摸输入并直接使内容移动。这不需要主线程执行任务,主线程执行的是 JavaScript、布局、样式或绘制。
但是,如果您附加一个输入处理程序,例如 touchstart、touchmove 或 touchend,则合成器线程必须等待此处理程序执行完成,因为您可能选择调用 preventDefault() 并且会阻止触摸滚动发生。即使没有调用 preventDefault(),合成器也必须等待,这样用户滚动会被阻止,这就可能导致卡顿和漏掉帧。
使用requestAnimationFrame节流比如:
function onScroll (evt) {
// Store the scroll value for laterz.
lastScrollY = window.scrollY;
// Prevent multiple rAF callbacks.
if (scheduledAnimationFrame)
return;
scheduledAnimationFrame = true;
requestAnimationFrame(readAndUpdatePage);
}
window.addEventListener('scroll', onScroll);
2.7 不要在输入处理程序中进行样式更改。
与滚动和触摸的处理程序相似,输入处理程序被安排在紧接任何 requestAnimationFrame 回调之前运行。
如果在这些处理程序之一内进行视觉更改,则在 requestAnimationFrame 开始时,将有样式更改等待处理。
比如:
function onScroll (evt) {
// Store the scroll value for laterz.
lastScrollY = window.scrollY;
// Prevent multiple rAF callbacks.
if (scheduledAnimationFrame)
return;
scheduledAnimationFrame = true;
requestAnimationFrame(readAndUpdatePage);
}
window.addEventListener('scroll', onScroll);
2.8、 使用webworker。参考Use web workers to run JavaScript off the browser's main thread
什么代码可以移到webworker:
Web Worker无法访问DOM和许多API,如WebUSB,WebRTC或Web Audio,因此您不能将依赖于此类访问的应用程序片段放入Worker中。尽管如此,移交给工作人员的每一小段代码都会在主线程上留出更多空间来存放必须存在的内容,例如更新用户界面。
数据管理和游戏中的计算逻辑、一些纯粹的算法等等可以放在webworker中。
2.9、 优化关键渲染路径。参考关键渲染路径 | Web | Google Developers
从收到 HTML、CSS 和 JavaScript 字节到对其进行必需的处理,从而将它们转变成渲染的像素这一过程中有一些中间步骤,优化性能其实就是了解这些步骤中发生了什么 - 即关键渲染路径。
以图为例:

优化关键渲染路径的常规步骤如下
对关键路径进行分析和特性描述: 资源数、字节数、长度。
最大限度减少关键资源的数量: 删除它们,延迟它们的下载,将它们标记为异步等。
优化关键字节数以缩短下载时间(往返次数)。
优化其余关键资源的加载顺序: 您需要尽早下载所有关键资产,以缩短关键路径长度。
具体方法可以参考:PageSpeed 规则和建议 | Web | Google Developers
比如React就可以参考:react怎么控制渲染顺序?
2.10 async/defer脚本
异步资源不会阻塞文档解析器,让浏览器能够避免在执行脚本之前受阻于 CSSOM。通常,如果脚本可以使用 async 属性,也就意味着它并非首次渲染所必需。可以考虑在首次渲染后异步加载脚本。
2.11 避免服务器同步调用
使用 navigator.sendBeacon() 方法来限制 XMLHttpRequests 在 unload 处理程序中发送的数据。 因为许多浏览器都对此类请求有同步要求,所以可能减慢网页转换速度,有时还很明显。 以下代码展示了如何利用 navigator.sendBeacon() 向 pagehide 处理程序而不是 unload 处理程序中的服务器发送数据。
<script>
function() {
window.addEventListener('pagehide', logData, false);
function logData() {
navigator.sendBeacon(
'https://putsreq.herokuapp.com/Dt7t2QzUkG18aDTMMcop',
'Sent by a beacon!');
}
}();
</script>
3 样式方面优化
3.1、缩小样式计算的范围并降低其复杂性。参考缩小样式计算的范围并降低其复杂性 | Web | Google Developers
通过添加和删除元素,更改属性、类或通过动画来更改 DOM,全都会导致浏览器重新计算元素样式,在很多情况下还会对页面或页面的一部分进行布局(即自动重排)。这就是所谓的计算样式的计算。
降低选择器的复杂性;使用以类为中心的方法,例如 BEM。
减少必须计算其样式的元素数量。
3.2、避免复杂布局和抖动。参考避免大型、复杂的布局和布局抖动 | Web | Google Developers
布局的作用范围一般为整个文档。
DOM 元素的数量将影响性能;应尽可能避免触发布局。
评估布局模型的性能;新版 Flexbox 一般比旧版 Flexbox 或基于浮动的布局模型更快。
避免强制同步布局和布局抖动;先读取样式值,然后进行样式更改。(使用类似fastDom的工具)
3.3、 确保文本在webfont加载期间保持可见
font-display:swap
Ensure text remains visible during webfont load
@font-face {
font-family: 'Pacifico';
font-style: normal;
font-weight: 400;
src: local('Pacifico Regular'), local('Pacifico-Regular'), url(https://fonts.gstatic.com/s/pacifico/v12/FwZY7-Qmy14u9lezJ-6H6MmBp0u-.woff2) format('woff2');
font-display: swap;
}
3.4、控制样式层。参考坚持仅合成器的属性和管理层计数 | Web | Google Developers
坚持使用 transform 和 opacity 属性更改来实现动画。
使用 will-change 或 translateZ 提升移动的元素。
避免过度使用提升规则;各层都需要内存和管理开销。
3.5、简化绘制的复杂度、减小绘制区域。参考简化绘制的复杂度、减小绘制区域 | Web | Google Developers
减少绘制区域往往是编排您的动画和变换,使其不过多重叠,或设法避免对页面的某些部分设置动画。
在谈到绘制时,一些绘制比其他绘制的开销更大。例如,绘制任何涉及模糊(例如阴影)的元素所花的时间将比(例如)绘制一个红框的时间要长。但是,对于 CSS 而言,这点并不总是很明显: background: red; 和 box-shadow: 0, 4px, 4px, rgba(0,0,0,0.5); 看起来不一定有截然不同的性能特性,但确实很不相同。
3.6、提取关键css。参考Extract critical CSS
将关键的css内联,不再走外部资源,可以加快。
使用penthouse或者critical等工具,将关键css内联到html中,提高FCP。
3.7、缩小css。参考Minify CSS
压缩css到最小
3.8、延迟非关键css。参考延迟非关键css
先加载首屏的css
通过Coverage面板来调试。绿色是关键、红色是非关键。
<link rel="preload" href="styles.css" as="style" onload="this.onload=null;this.rel='stylesheet'">
<noscript>
<link rel="stylesheet" href="styles.css">
</noscript>
3.9 将 CSS 置于文档 head 标签内
尽早在 HTML 文档内指定所有 CSS 资源,以便浏览器尽早发现 <link>标记并尽早发出 CSS 请求。
3.10 避免使用 CSS import 一个样式表可以使用 CSS import (@import) 指令从另一样式表文件导入规则。不过,应避免使用这些指令,因为它们会在关键路径中增加往返次数: 只有在收到并解析完带有 @import 规则的 CSS 样式表之后,才会发现导入的 CSS 资源。
4 图片资源相关
4.1、响应式图片。参考:Optimize CSS background images with media queries
响应式图片,不同屏幕加载不同图片。
4.2、使用正确的图片格式。参考Choose the right image format
优先使用webp格式,用imagemin-webp这种工具。
png大小会稍微大点,不会压缩,jpg会小点做一定压缩。
4.3、选择正确的压缩级别。参考Choose the correct level of compression
svg图片通过svgo这样的工具来压缩。
png、jpg等进行一定的有损或无损压缩。配合自动化工具。
压缩工具imagemin、jimp、sharp等等、
4.4、使用video取代gif。参考Replace animated GIFs with video for faster page loads
使用ffmpeg将gif变成mp4和webm格式,提高性能,降低文件大小。
5、代码层面的优化
比如有做过哪些ssr性能方面的优化?中提到的异步优化和缓存优化,和做过哪些react方面的性能优化?中React防止组件重复渲染的memo等方式。
serviceworker做了什么实践?
可以参考文章:serviceworker运用与实践 · Issue #2 · omnipotent-front-end/blog
被以下收录:
体验优化
业务上做过哪些优化用户体验的事情?
直播活动,商品详情页访问量大,页面加骨骼屏,等待时间过长时loading引导客户先去其他活动转转,不让用户盲等。
对于无论是H5还是小程序,埋点数据全部走离线上传,把埋点队列里的埋点请求全部放在缓存里,一个一个慢慢发送慢慢吐泡泡,既保证了不与主流程业务请求竞争,也不会因为用户设备退出应用闪退,而侦测不到数据,因为下次进入时只要缓存里有没吐完的泡泡(埋点请求队列)就继续发送。
应用的业务http请求封装一层 熔断任务队列,增加重试机制,增加token自动刷新请求等等。
应用页面适当的缓动动画,不仅可以为请求数据争取时间,还可以提高用户体验,不那么突兀。
H5可使用龙骨动画、spine动画,小程序可以使用帧动画、css animation提高页面的动感,以及一定的互动营销效果。从实现和编码方面都比裸写DOM要好得多。
异常
怎么做异常监控?
私有化部署sentry。
Sentry接入时,除了引入SDK,需要做什么其他事情?
1、sourcemap上传方便定位代码。可以通过webpack插件或者手动上传。
2、在接口拦截器或其他位置上报异常,自定义异常上传方式。
3、区分环境、测试和线上或者预发。
4、用户user设置,Sentry.setUser({ id: user.id }),方便区分用户信息,用来复现。
5、去除噪音
6、对监控数据、配置告警阈值等方式,结合邮件、机器人等方式推送到相关的人员,来及时发现并解决问题。
7、关联 BUG 管理系统、自动生成 BUG 单,将 BUG 单绑定到对应的版本分支上,通过提交对应的修复分支、进行测试验证后,自动地扭转 BUG 单状态。
参考:
前端异常监控 Sentry 的私有化部署和使用-云社区-华为云
Sentry怎么去除噪音?
1、SDK处可以设置一些节流的参数
// 高访问量应用可以控制上报百分比
tracesSampleRate: 0.3,
2、系统的GUI里也可以设置,发送邮件的条件比如说时间间隔内出现次数等。
3、设置一些域名白名单或者黑名单,第三方SDK的报错一般不用关注。
谈谈你对SourceMap的理解?
Source Map。它是一个独立的map文件,与源码在同一个目录下。
简单说,Source map就是一个信息文件,里面储存着位置信息。也就是说,转换后的代码的每一个位置,所对应的转换前的位置。
有了它,出错的时候,除错工具将直接显示原始代码,而不是转换后的代码。
参考:
JavaScript Source Map 详解 - 阮一峰的网络日志
能聊一聊Script error出现的原因么?
跨域脚本的异常是捕获不到的,只是抛出来Script error,增加crossorigin="anonymous"属性就好了,当然脚本cdn那边跨域请求头也是需要的
参考:
“Script error.”的产生原因和解决办法_“Script error.”的产生原因和解决办法_前端监控_应用实时监控服务ARMS - 阿里云
移动适配
移动端高清屏解决方案是什么样子?
- 移动端适配:flexible
原理就是在不同机型下给body挂不同字体大小,页面样式通过rem对应来完成。
- 多倍图
视口不缩放:使用@2x两倍图
视口缩放:根据不同的dpr,加载不同尺寸的图片(图片处理服务器)
- 1px边框问题
多种解决方案,参考codepen
使用box-shadow
-webkit-box-shadow:0 1px 1px -1px rgba(0, 0, 0, 0.5);
缺点:颜色不便控制,太淡,有虚边
使用background-image
background-image:
linear-gradient(180deg, red, red 50%, transparent 50%),
linear-gradient(270deg, red, red 50%, transparent 50%),
linear-gradient(0deg, red, red 50%, transparent 50%),
linear-gradient(90deg, red, red 50%, transparent 50%);
background-size: 100% 1px,1px 100% ,100% 1px, 1px 100%;
background-repeat: no-repeat;
background-position: top, right top, bottom, left top;
缺点:不能实现圆角1px效果,css需要做兼容处理
使用border-image
border-image:url("data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAAECAYAAABP2FU6AAAAGXRFWHRTb2Z0d2FyZQBBZG9iZSBJbWFnZVJlYWR5ccllPAAAAB5JREFUeNpiPnH8zH/G////MzAxAAHTyRNn/wMEGABpvQm9g9TJ1QAAAABJRU5ErkJggg==") 2 0 stretch;
border-width:0px 0px 1px;
border-style: solid;
缺点:边框颜色不便修改
伪类:after & transform: scale(0.5)
.box4
position relative
&:after
content ''
display block
position absolute
top -50%
left -50%
bottom -50%
right -50%
border 1px solid red
-webkit-transform scale(0.5)
transform scale(0.5)
缺点:占用了伪类,容易和原样式冲突
使用0.5px适配ios8以上的iPhone机型
@media (-webkit-min-device-pixel-ratio:2){
.box5 {border-width:.5px}
}
缺点:只适用于ios8+以上的iOS系统,安卓机不支持0.5px
参考:
逻辑像素和物理像素的区别?
相同问题:设备像素、css-像素、设备独立像素、dpr、ppi-之间的区别
物理像素:设备屏幕实际拥有的像素点。
比如iPhone 6的屏幕在宽度方向有750个像素点,高度方向有1334个像素点,所以iPhone 6 总共有750*1334个物理像素。
逻辑像素:也叫“设备独立像素”(Device Independent Pixel, DIP),可以理解为反映在CSS/JS代码里的像素点数。
设备像素比(Device Pixel Ratio, DPR):一个设备的宽或高方向上,物理像素与逻辑像素之比,即:
DPR = width物理 / width逻辑 = height物理 / height逻辑。
举个例子,iPhone 6的物理像素上面已经说了,是750*1334,那它的逻辑像素呢?我们只需在iPhone 6的Safari里打印一下screen.width和screen.height就知道了,结果是 375*667,这就是它的逻辑像素,据此很容易计算出DRP为2。当然,我们还可以直接通过window.devicePixelRatio这个值来获取DRP,打印结果是2,符合我们的预期。
“设计像素”:(奇葩的iPhone 6 Plus)
现象:以iPhone 6 Plus为例,它的实际物理像素点个数是1080*1920,但如果你截个屏,你会发现截屏图片的宽高是1242*2208;浏览器的screen对象会告诉你,6 Plus的逻辑像素是414*736,正好是截屏宽度的三分之一,DPR值也为3。
原因:iPhone 6 Plus系统定义的屏幕像素就是12422208,系统会自动把这些像素点塞进10801920个实际像素点来渲染。对于前端来说,可以直接把1242视为6 Plus的 “物理像素”,包括UE小姐姐们出图也是以1242为标准的,因此不妨把1242*2208称为6 Plus的 “设计像素”。
苹果这是要闹那样? 其实,当初苹果公司在确定6 Plus的DRP时,纠结了半天:选2吧,同样的字号在6 Plus上看起来比6更小,不好;选3吧,字又显得太大了,导致一屏能展示的内容还没有6多;最适合视觉的DRP值是2.46,但这样一个数字能把设计师和程序员们逼疯。最后就想出了引入“设计像素”这样一个两全其美的方案,既让开发者开心,又让用户爽,岂不美哉?
PPI:每英寸拥有的物理像素的数量
参考:
CSS中的px与物理像素、逻辑像素、1px边框问题 - 大唐西域都护 - 博客园
为什么会出现1px的边框问题?怎么解决?
首先了解逻辑像素和物理像素的区别?。
在苹果的带动下,Retina技术在移动设备上已经成了标配,所以前端攻城狮必须直面如下事实:
- 你想画个1px的下边框,但屏幕硬是塞给你一条宽度为2—3个物理像素的线,看起来比较粗。
- 你没法像安卓或iOS的同事那样直接操纵物理像素点。
这就是初级前端面试必考题之“1px边框问题”的由来。
1px边框问题的解法千奇百怪,各显神通,但以我的实践经验,最推崇的方法还是利用CSS3的transform: scale,因为简单直接、适用性和兼容性好。
你不是给我两个物理像素点吗?加个transform: scale(0.5),只剩一个点了~
三个物理像素点?那就scale(0.33)!
使用CSS的-webkit-min-device-pixel-ratio媒体查询可以针对不同的DPR做出处理
@media (-webkit-min-device-pixel-ratio:2),(min-device-pixel-ratio:2){
.border-bt-1px(@color) {
position: relative;
&::after {
position: absolute;
bottom: 0;
width: 100%;
height: 1px;
background-color: @color;
transform: scaleY(0.5);
}
}
}
参考:
CSS中的px与物理像素、逻辑像素、1px边框问题 - 大唐西域都护 - 博客园
使用rem布局的优缺点是什么?
优点:
在屏幕分辨率千差万别的时代,只要将 rem 与屏幕分辨率关联起来就可以实现页面的整体 缩放,使得在设备上的展现都统一起来了。 而且现在浏览器基本都已经支持 rem 了,兼容性也非常的好。
缺点:
(1)在奇葩的 dpr 设备上表现效果不太好,比如一些华为的高端机型用 rem 布局会出现错乱。
(2)使用 iframe 引用也会出现问题。
(3)rem 在多屏幕尺寸适配上与当前两大平台的设计哲学不一致。即大屏的出现到底是为 了看得又大又清楚,还是为了看的更多的问 题。
视觉视口(visual viewport)和布局视口(layout viewport)的区别
移动端出现这两个viewport的原因:
移动端的viewport比桌面的viewport小,导致移动端的网页显示有问题。(桌面浏览器上viewport是严格等于浏览器的窗口)现实中很少会有网站去特别迎合移动端。所以就出现这两个viewport
visual viewport:
visual viewport是当前显示在屏幕上的页面的一部分。用户可以滚动来改变他看到的页面部分,或者缩放来改变visual viewport的大小。
layout viewport:
CSS布局,尤其是百分比宽度,是相对于layout viewport计算的,layout viewport可以比visual viewport宽得多。
<html>元素最初采用layout viewport的宽度(不用style指定的话),而您的CSS被解释为屏幕明显比手机屏幕宽。这可以确保你的网站布局和在桌面浏览器上一样。
layout viewport有多宽?每个浏览器的情况都不一样。Safari iPhone使用980px, Opera 850px, Android WebKit 800px, IE 974px。
缩放
这两个viewport单位都是CSS像素。visual viewport的尺寸会随着缩放而改变,但layout viewport的尺寸保持不变。(如果改变,页面会重排,因为百分比宽度需重新计算)
layout viewport大小
document.documentElement.clientWidth和-Height为layout viewport的尺寸。
document.documentElement.offsetWidth/Height是HTML的尺寸。
document.documentElement实际上就是<html>元素。
在pc端
document. documentElement. clientWidth/Height只会给出viewport的尺寸,而不管<html>元素尺寸如何改变
visual viewport大小
visual viewport为window.innerWidth/innerHeight。当用户缩小或缩小时,测量值会发生变化,因为屏幕上的CSS像素大小不同。不幸的是,它的兼容性没有得到很好的支持。
指定layout viewport的大小
添加标签:
<!-- 1.设为设备大小 -->
<meta name="viewport" content="width=device-width,initial-scale=1.0">
<!-- 2.确定的大小 -->
<meta name="viewport" content="width=320">
如果指定html的大小,而这个大小若小于layout viewport,会导致初始时界面上有很大一块空白。所以大小需设在layout viewport
参考
Difference between visual viewport and layout viewport?
A tale of two viewports — part two
Flexible方案
- 使用一款 postcss 插件postcss-pxtorem将px单位转化为rem(依据配置的rootValue)
- 用lib-flexible 判断设备设置 rem 基准值,做的事如下:
- 动态改写
<meta>标签 - 给
<html>元素添加data-dpr属性,并且动态改写data-dpr的值 - 给
<html>元素添加font-size属性,并且动态改写font-size的值
- 动态改写
将视觉稿宽度分为100份(主要为了以后能更好的兼容vh和vw),总宽为100a=10rem。375px的视觉稿就设置rootValue为37.5px(即1rem的大小)
rem方案的配置如这次提交
使用vm方案怎么做移动端适配?
vw:是Viewport's width的简写,1vw等于window.innerWidth的1%
vh:和vw类似,是Viewport's height的简写,1vh等于window.innerHeihgt的1%
vmin:vmin的值是当前vw和vh中较小的值
vmax:vmax的值是当前vw和vh中较大的值
如果设计稿用750px宽度的,100vw = 750px,即1vw = 7.5px。那么我们可以根据设计图上的px值直接转换成对应的vw值。
使用一款 PostCSS 插件postcss-px-to-viewport将 px 单位转化为 vw/vh 单位。(依据配置的viewportWidth)
参考
viewport方案的配置如这次提交
移动web为什么有300ms延迟,怎么解决?
该问题没有了: 移动端300ms延迟被取消了
300ms的原因在于:由于移动端会有双击缩放的这个操作,因此浏览器在click之后要等待300ms,看用户有没有下一次点击,也就是这次操作是不是双击。
解决方案:
1、禁用缩放
由于是缩放导致的延迟判断逻辑,所以在meta中声明禁止缩放,浏览器就可以放弃这段识别逻辑了。
<meta name="viewport" content="user-scalable=no">
<meta name="viewport" content="initial-scale=1,maximum-scale=1">
2、touch-action
touch-action这个CSS属性。这个属性指定了相应元素上能够触发的用户代理(也就是浏览器)的默认行为。如果将该属性值设置为touch-action: none,那么表示在该元素上的操作不会触发用户代理的任何默认行为,就无需进行300ms的延迟判断,可惜目前safari还不支持。
3、第三方库手动判断
比如fastclick,实现原理是在检测到touchend事件的时候,会通过DOM自定义事件立即出发模拟一个click事件,并把浏览器在300ms之后的click事件阻止掉。
参考:
什么是点透问题,如何解决呢?
该问题没有了: 移动端300ms延迟被取消了
先理解了移动web为什么有300ms延迟,怎么解决?,既然click点击有300ms的延迟,那对于触摸屏,我们直接监听touchstart事件不就好了吗?
使用touchstart去代替click事件有两个不好的地方。
第一:touchstart是手指触摸屏幕就触发,有时候用户只是想滑动屏幕,却触发了touchstart事件,这不是我们想要的结果;
第二:使用touchstart事件在某些场景下可能会出现点击穿透的现象。
点透就是说:
假如页面上有两个元素A和B。B元素在A元素之上。我们在B元素的touchstart事件上注册了一个回调函数,该回调函数的作用是隐藏B元素。我们发现,当我们点击B元素,B元素被隐藏了,随后,A元素触发了click事件。
这是因为在移动端浏览器,事件执行的顺序是touchstart > click。而click事件有300ms的延迟,当touchstart事件把B元素隐藏之后,隔了300ms,浏览器触发了click事件,但是此时B元素不见了,所以该事件被派发到了A元素身上。如果A元素是一个链接,那此时页面就会意外地跳转。
参考:移动端浏览器点击事件触发顺序。 移动浏览器事件触发顺序为:
touchstart --> touchmove --> touchend --> mouseover(有的浏览器没有实现) --> mousemove(一次) -->mousedown --> mouseup --> click
解决方案:
1、只用touch
最简单的解决方案,完美解决点击穿透问题把页面内所有click全部换成touch事件(touchstart、’touchend’、’tap’),需要特别注意a标签,a标签的href也是click,需要去掉换成js控制的跳转,或者直接改成span + tap控制跳转。如果要求不高,不在乎滑走或者滑进来触发事件的话,span + touchend就可以了,毕竟tap需要引入第三方库。
2、只用click
会带来300ms延迟,页面内任何一个自定义交互都将增加300毫秒延迟。 不用touch就不会存在touch之后300ms触发click的问题,如果交互性要求不高可以这么做。
3、使用第三方库
比如fastclick,实现原理是在检测到touchend事件的时候,会通过DOM自定义事件立即出发模拟一个click事件,并把浏览器在300ms之后的click事件阻止掉。
参考:
移动端300ms延迟被取消了
方案1:
加上如下标签:
<meta name="viewport" content="width=device-width">
这将视口宽度设置为与设备相同,这通常是移动优化站点的最佳实践。有了这个标记,浏览器就会假定您已经让文本在移动设备上可读了,为了更快地点击,双点缩放功能被取消了。
只有少数移动端浏览器不兼容。手机访问测试地址 点击Google字符是否反应很慢,来测试是否是那少数。
方案2:
如果因为某些原因你不能做出这种改变,你可以使用touch-action: manipulation在整个页面或特定元素上实现相同的效果:
html {
touch-action: manipulation;
}
Firefox不支持这种技术,所以viewport标记更受欢迎。
你有做过Hybrid APP开发吗?说说你的经验(todo)
在公司移动端和PC端都做过相应的开发,然后就介绍了移动端开发的一些东西,然后说了下H5是如何和客户端进行交互的,最后说了下自己参与的一些weex开发项目,说了下weex与H5的区别。
Hybrid离线方案你们是怎么做
可以通过把整个前端资源加载到app内去,由app渲染,最后h5只发请求数据即可、jscsshtml均存在与app内。
也可以通过前端打包提供元数据,在app启动时去预加载来映射。
离线化技术可以将网页的网络加载时间变为 0,在离线化的选型上美团点评内部有很多选择,我们也在不同的方向进行尝试。其中我们的选择包括:
标准技术:
Application Cache:实现上各个平台各个浏览器有一些差异,即使把“无法更新的坑”踩过还是会有很多“无法离线”的坑,PASS
Service Workers:Service Workers 是团队一直跟进的技术,目前在测试已经接近正式发布,只是在 iOS 上还无法大范围使用,长期看好,暂时 PASS 借助 Native 能力的自有技术:
美团平台技术团队的类 Service Workers 的被动离线化技术
美团旅行技术团队的离线包技术
留下来的只剩下两个自有技术,这两个技术的最大区别是,是否解决了首次加载问题?离线化方案的首次加载问题是一个很难的技术领域,我认为其最核心的问题是何时加载,提前加载会不会用户在很长一段时间内都不会用到导致浪费流量?使用包含首次加载优化的离线化技术的项目多了会不会造成加载拥塞?是不是需要分析用户行为数据去更精准的进行离线包的提前加载?这当中存在太多不确定性,不过我相信我们的技术团队一定能够想出优美的解决方案去解决这个问题。
另外基于 Native 能力的离线化技术还存在一些来自平台的限制,如 iOS 的 WKWebView 不支持请求拦截,而请求拦截是离线化的关键技术,这个原因导致在 WKWebView 上无法实现离线化。
WKWebView 的优势是:运行和渲染速度更快,与 Safari 内核一致 Apple 重点迭代跟进问题;劣势是:启动速度慢,无法拦截请求进而使用自有的离线化技术。
权衡离线化所带来的巨大优势和 WKWebView 的速度优势,我们选择继续使用 UIWebView。(曾经在 iOS 11 发布前业界一度认为 Apple 会在 iOS 11 中支持 WKWebView 的请求拦截)
参考:
Hybrid App 离线包方案实践 · Issue #63 · mcuking/blog
hybrid发接口,一般怎么处理?
通过封装sdk,在h5就fetch或xmlhttprequest,在app内就走jsbridge发接口。
之所以要走jsbridge发接口,有以下几点:
1、方便app做统一处理,拦截操作,jwt鉴权;
2、方便app提供下载功能时,能不再发请求而是读取本地数据。
3、方便webview优化,提前预加载接口数据。
唤起app的原理
1、URL Scheme
就像给服务器资源分配一个 URL,以便我们去访问它一样,我们同样也可以给手机APP分配一个特殊格式的 URL,用来访问这个APP或者这个APP中的某个功能(来实现通信)。APP得有一个标识,好让我们可以定位到它,它就是 URL 的 Scheme 部分。
2、Universal Link
Universal Link 是苹果在 WWDC2015 上为 iOS9 引入的新功能,通过传统的 HTTP 链接即可打开 APP。如果用户未安装 APP,则会跳转到该链接所对应的页面。
通过iframe/a/window.top.location.href等多种方式来尝试赋值唤起。具体实现可以参考:callapp-lib的实现
如何判断唤起是否成功
通过判断当前页面是否被激活页面来判断,至于如何判断当前页面被激活状态,APP 如果被唤起的话,页面就会进入后台运行,setInterval 在 ios 中不会停止运行,在 android 中停止运行。
每 20ms 执行一次,执行 100次 在页面中实际耗费与 2000 ms 不会相差多少。
我们的判断条件比预期时间多设置了 500ms,所以如果安卓中 setInterval 内的函数执行 100 次以内所费时间超过 2500ms,则说明 APP 唤起成功,反之则代表失败。
我们通过 document.hidden 和 document.webkitHidden 属性来判断 APP 在 ios 中是否被正常唤起,2000ms 内,页面转入后台运行,document.hidden 会返回 true,代表唤端成功,反之则代表失败。
参考:
h5怎么和app通信的
JavaScript 调用 Native 的方式,主要有两种:注入 API 和 拦截 URL SCHEME。
注入 API 方式的主要原理是,通过 WebView 提供的接口,向 JavaScript 的 Context(window)中注入对象或者方法,让 JavaScript 调用时,直接执行相应的 Native 代码逻辑,达到 JavaScript 调用 Native 的目的。
拦截 URL SCHEME 的主要流程是:Web 端通过某种方式(例如 iframe.src)发送 URL Scheme 请求,之后 Native 拦截到请求并根据 URL SCHEME(包括所带的参数)进行相关操作。
Native调用js的方式:直接调用api执行js拼接的字符串。
参考:
jsbridge有安全问题吗?怎么避免?
以安卓 webview 的 addJavascriptInterface 为例,在安卓 4.2 版本之前,js 可以利用 java 的反射 Reflection API,取得构造该实例对象的类的內部信息,并能直接操作该对象的内部属性及方法,这种方式会造成安全隐患,例如如果加载了外部网页,该网页的恶意 js 脚本可以获取手机的存储卡上的信息。
在安卓 4.2 版本后,可以通过在提供给 js 调用的 java 方法前加装饰器 @JavascriptInterface,来表明仅该方法可以被 js 调用。
避免方式就是敏感操作放在native端去实现。
参考:
JSBridge 实现原理解析 - SegmentFault 思否
webview请求预加载
webview的优化有两个方向,一个是webview控件自己在app启动时预热,一个是webview在启动的同时去请求一些h5需要的接口。
这两个都是客户端开发需要去完成的内容,其中需要前端配合的点在于,webview中页面的接口需要走统一的拦截器发送请求(jsbridge)。
从而告诉客户端页面有哪些请求,方便客户端去提前下载。以及每次请求时可以判断到底去远端拿,还是从app内的缓存去取。
参考:
聊一下近一年大前端发展趋势,未来走向,如何关注的,然后请总结下端内前端的核心痛点,你怎么解决?
趋势和方向:跨端和提效,知识结构广度和深度两个方向发展
端内前端核心痛点:在开发效率和性能、兼容性上取得平衡
解决:flutter思路或者小程序思路
flutter思路:自绘引擎
小程序思路:定制语法,定制浏览器
大屏幕如何适配
大屏幕适配需要从以下几个方面入手,第一个是宽高、第二个是字体大小、第三个是三方库的设置。
1.针对宽高:
从最外层到最内部的所有盒模型布局相关(margin/padding/width/height),全部用百分比来完成,部分无法撑开的高度可以用vh来完成。
2.针对字体大小:
需要使用rem,并封装对应的flexible,根据视觉稿来对应
举个例子:
const baseSize = 16
// 设置 rem 函数
function setRem () {
const scale = document.documentElement.clientWidth / 1920
document.documentElement.style.fontSize = baseSize * Math.min(scale) + 'px'
}
// 初始化
setRem()
// 改变窗口大小时重新设置 rem
window.onresize = function () {
setRem()
}
同时封装css预处理器相关函数:
@function pxTorem($px){// 默认16px
@return $px / 16 * 1rem;
}
3.针对三方库
有些三方库设置的时候是以像素为主的,故而在大屏视频中,需要手动计算,故而我们需要在resize时做一段逻辑,拿到一个charScale的缩放比例,这里以vue的mixin为例子:
import _ from 'lodash'
export default {
data() {
return {
charScale: 0.5
}
},
mounted() {
this.__resizeHandler = _.debounce(() => {
const clientWidth = document.body.clientWidth
if (clientWidth) {
this.charScale = clientWidth / 1920
}
}, 100)
window.addEventListener('resize', this.__resizeHandler)
this.charScale = document.body.clientWidth ? document.body.clientWidth / 1920 : 1
},
beforeDestroy() {
window.removeEventListener('resize', this.__resizeHandler)
},
methods: {
// use $_ for mixins properties
// https://vuejs.org/v2/style-guide/index.html#Private-property-names-essential
$_sidebarResizeHandler(e) {
if (e.propertyName === 'width') {
this.__resizeHandler()
}
}
}
}
框架选型
Vue和React的区别是什么?
实现上,Vue跟React的最大区别在于数据的reactivity,就是反应式系统上。Vue提供反应式的数据,当数据改动时,界面就会自动更新,而React里面需要调用方法SetState。
Vue 使用的是 web 开发者更熟悉的模板与特性,比如Vue的单文件组件是以模板+JavaScript+CSS的组合模式呈现,它跟web现有的HTML、JavaScript、CSS能够更好地配合。React 的特色在于函数式编程的理念和丰富的技术选型。
事件系统不一致。React 事件系统庞大而复杂。其中,它暴漏给开发者的事件不是原生事件,是 React 包装过合成事件,并且非常重要的一点是,合成事件是池化的。也就是说不同的事件,可能会共享一个合成事件对象。另外一个细节是,React 对所有事件都进行了代理,将所有事件都绑定 document 上。而Vue 事件处理函数中的 this 默认指向组件实例。从事件 API 上我们就能看出前端框架在设计的一个不同思路: React 设计是改变开发者,提供强大而复杂的机制,开发者按照我的来;Vue 是适应开发者,让开发者怎么爽怎么来。
参考:
React相比Vue的优势在哪里?
1、强大的生态
2、灵活的书写方式,可以创造更多的灵感
3、数据非响应式,更容易排查问题,维护性更高
4、react、reactnative可以跨端,有大厂背书,生态非常重要
Vue相比React的优势在哪里?
1、数据响应式决定了可以减少很多手动优化的工作。
Vue 进行数据拦截/代理,它对侦测数据的变化更敏感、更精确,也间接对一些后续实现(比如 hooks,function based API)提供了很大的便利。
但是 React 并不知道什么时候“应该去刷新”,触发局部重新变化是由开发者手动调用 setState 完成。。React setState 引起局部重新刷新。为了达到更好的性能,React 暴漏给开发者 shouldComponentUpdate 这个生命周期 hook,来避免不需要的重新渲染(相比之下,Vue 由于采用依赖追踪,默认就是优化状态:你动了多少数据,就触发多少更新,不多也不少,而 React 对数据变化毫无感知,它就提供 React.createElement 调用已生成 virtual dom)。另外 React 为了弥补不必要的更新,会对 setState 的行为进行合并操作。因此 setState 有时候会是异步更新,但并不是总是“异步”。
2、模板编码效率更高
模板和渲染函数的弹性选择。
3、性能
更快的渲染速度
什么时候用Vue,什么时候用React?
对可维护性要求较高可以用Vue,对生态要求较高可以用React。
svelte有没有了解过?
有一套自己的模板DSL,可以做到没有runtime,或者说少量runtime。适合做一写组件比如video-player等等的,在其他人引用时不依赖其他前端框架的组件。
Svelte 比较有优势的地方,就是用来编译可独立分发的 Web Components。传统框架和 Web Components 结合最大的问题就在于运行时:单独分发的 WC 里面直接打包框架运行时,等于每个组件都要复制一份框架;不打包的话,又做不到开箱即用。但 Svelte 受这个问题的限制最小(依然存在重复代码问题,但取决于你用了多少功能),可以说是最适合这个用例的框架。
组件库建设
介绍一下组件库的建设
先说了组件库之前用create-react-app搭建但是觉得太臃肿,然后自己搭建了一个,介绍了组件库用到的的技术栈,支持的三种模块方式,按需加载功能,自定义主题色功能,tsconfig的配置,commit规范和代码格式规范等等
参考:
金九银十:一年前端的字节三面面经 - SegmentFault 思否
组件库怎么支持多个模块规范依赖?我引入import组件的时候怎么知道引入哪种模块化方式的组件?
package.json的main字段的commonjs的规范入口,module是esmodule的规范入口。打包则是通过打包工具打包成不同的规范dist。
你组件库用了ts,那么我使用组件库的时候是怎么引用你的声明文件的?
package.json的typings字段
参考:
金九银十:一年前端的字节三面面经 - SegmentFault 思否
组件怎么按需加载?
通过支持es模块,这个模块就是简单babel编译成es5语法,但是对import export字段不进行编译,然后package.json声明sideEffect字段来声明副作用文件,防止被tree-shaking掉,项目中我们可以利用打包工具的tree-shaking功能做到按需加载
参考:
金九银十:一年前端的字节三面面经 - SegmentFault 思否
组件样式怎么按需加载?
babel-import-plugin,这时候才想起来,跟面试官解释了自己的组件内不会引入样式,而是基于glup流式构建单独处理less文件,这样做的好处就是支持babel-import-plugin
参考:
金九银十:一年前端的字节三面面经 - SegmentFault 思否
组件规范怎么保持?
介绍了eslint,(顺便说了不选择tslint的原因),prettier,以及commit规范,另外说到了git-hook,提交前会进行检查并且格式化(format)
参考:
金九银十:一年前端的字节三面面经 - SegmentFault 思否
组件包版本是怎么维护的,3位数分别代表什么?
一般是通过语义化版本 2.0.0 | Semantic Versioning,这套规范来维护的。
版本格式:主版本号.次版本号.修订号,版本号递增规则如下:
主版本号:当你做了不兼容的 API 修改,
次版本号:当你做了向下兼容的功能性新增,
修订号:当你做了向下兼容的问题修正。
先行版本号及版本编译元数据可以加到“主版本号.次版本号.修订号”的后面,作为延伸。
业务组件的单元测试一般需要测试什么内容?
可以参考FunnyLiu/element at readsource,也就是elementui的单元测试部分。
主要通过不同的参数传递后、或者执行了组件的不同api后,组件dom是否有对应的class或text来判断流程是否正确。性能测试(比如select的200个option的渲染时间不超过1s)。
组件封装有哪些原则?
组件开发中,如何将数据和UI解耦,是最重要的工作。
1、单一职责
你的组件是否符合只实现一个职责,并且只有一个改变状态的理由?
如fetch请求和渲染逻辑,应该分离。因为fetch请求时会造成组件重新渲染,渲染时的样式或数据格式变化,也会引起组件重新渲染。
单一职责可以保证组件是最细的粒度,且有利于复用。但太细的粒度有时又会造成组件的碎片化。
因此单一职责组件要建立在可复用的基础上,对于不可复用的单一职责组件,我们仅仅作为独立组件的内部组件即可。
2、通用性
放弃对DOM的掌控,只提供最基础的DOM、交互逻辑,将DOM的结构转移给开发者
3、封装
良好的组件封装应该隐藏内部细节和实现意义,并通过props来控制行为和输出。
减少访问全局变量:因为它们打破了封装,创造了不可预测的行为,并且使测试变得困难。可以将全局变量作为组件的props,而不是直接引用。
4、纯函数纯组件
非纯组件有显示的副作用,我们要尽量隔离非纯代码。
将全局变量作为props传递给组件,而非将其注入到组件的作用域中。
将网络请求和组件渲染分离,只将数据传递给组件,保证组件职责的单一性,也能将非纯代码从组件中隔离。
5、可测试性
测试不仅仅是自动检测错误,更是检测组件的逻辑。
如果一个组件测试不易于测试,很大可能是你的组件设计存在问题。
6、语义化
开发人员大部分时间都在阅读和理解代码,而不是实际编写代码。
有意义的函数、变量命名,可以让代码具有良好的可读性。
参考:
兼容性
什么是 Polyfill ?
Polyfill 指的是用于实现浏览器并不支持的原生 API 的代码。
比如说 querySelectorAll 是很多现代浏览器都支持的原生 Web API,但是有些古老的浏览 器并不支持,那么假设有人写了一段代码来实现这个功能使这些浏览器也支持了这个功能,那么 这就可以成为一个 Polyfill。
一个 shim 是一个库,有自己的 API,而不是单纯实现原生不支持的 API。
有哪些polyfill解决方案?
1、自己hack
最简单的是自己手写hack方法,方法在MDN上即可拿到,然后打包,自己引入自己的SDK来polyfill。
这样的优点是可控、轻量,缺点是不全,每次都需要补充、可维护性差。
2、基于node工具链路
基于@babel/polyfill或core-js这样的库,配合Browserslist来指定需要兼容的浏览器范围,最后打包到头部。
这样的优点是可控、轻量,缺点是比第一种方案稍微重一点,而且也是全量覆盖的,很多用户其实用不到。
3、基于服务来做
通过Polyfill.io这样的服务或者自己搭建相识的,根据浏览器不同版本来适配polyfill。
这样的优点是最精确定位问题,缺点是维护起来麻烦。
参考:
如何检测浏览器所支持的最小字体大小?
用 JS 设置 DOM 的字体为某一个值,然后再取出来,如果值设置成功,就说明支持。
命令行工具
有哪些常见的用到过的命令行交互包?
yargs或者commander来控制命令的注册和转发;
chalk来控制字体的颜色;
inquirer来控制一些选择或者提问;
ora来控制一些加载等状态
自己写的mock服务是怎么实现的,为什么不在webpack里用相关插件?
有好几个特性,首先是
它拥有以下功能:
1、通过配置文件.httpmockrc.json或者package.json文件中的httpmock字段来进行mock映射关系;
2、支持mockjs语法,灵活配置动态化的mock返回值;
3、基于path-to-regexp识别express风格的url
4、基于http-mockjs-ui,通过可视化的方式管理配置文件和mock文件内容,提高效率。
5、方便的初始化和GUI编辑体验。
6、支持mock和proxy跨域的接口,通过service worker
7、支持js定制复杂的规则。
8、支持对body参数的校验。
其中通过service worker进行跨域,对fetch进行拦截。
通过GUI完成快速的编辑。这些都是比较定制化的需求。再者就是为了锻炼开源的一些实践。
其实现原理就是将传入的app对象,进行app.all('/*'),进行拦截并进行mock等一系列判断。serviceworker的跨域支持则是通过注入sdk,注入sw.js来完成遥相呼应的。
SSR
SSR解决了什么问题?
首屏时间与SEO,SSR 本质上是用服务端压力换取首屏体验的提升。客户端渲染和服务器端渲染的结合,在服务器端执行一次,用于实现服务器端渲染(首屏直出),在客户端再执行一次,用于接管页面交互 (绑定事件),核心解决 SEO 和首屏渲染慢的问题。
SSR为啥在服务端执行一次,在客户端还需要执行一次?
原因很简单,服务端使用 renderToString 渲染页面,而 react-dom/server 下的 renderToString 并没有做事件相关的处理,因此返回给浏览器的内容不会有事件绑定,渲染出来的页面只是一个静态的 HTML 页面。只有在客户端渲染 React 组件并初始化 React 实例后,才能更新组件的 state 和 props,初始化 React 的事件系统,执行虚拟 DOM 的重新渲染机制,让 React 组件真正“ 动” 起来。
参考:
服务器端已经渲染了一次 React 组件,如果在客户端中再渲染一次 React 组件,会不会渲染两次 React 组件?
答案是不会的。秘诀在于 data-react-checksum 属性,如果使用 renderToString 渲染组件,会在组件的第一个 DOM 带有 data-react-checksum 属性,这个属性是通过 adler32 算法算出来:如果两个组件有相同的 props 和 DOM 结构时,adler32 算法算出的 checksum 值会一样,有点类似于哈希算法。
所以当客户端渲染 React 组件时,首先计算出组件的 checksum 值,然后检索 HTML DOM 看看是否存在数值相同的data-react-checksum属性,如果存在,则组件只会渲染一次,如果不存在,则会抛出一个 warning 异常。也就是说,
当服务器端和客户端渲染具有相同的 props 和相同 DOM 结构的组件时,该 React 组件只会渲染一次。
参考:
SSR会有哪些坑以及如何解决?
cpu/memory 可能爆了,出现异常不好定位调试,带权限接口与非权限接口有可能需要剥离(为了缓存),TTFB慢了(如果不加缓存,以前可能是骨架屏,现在直接白屏),由于需要起http服务工程上也复杂了很多
SSR双端是怎么构建的?有什么区别?
为了解决node端引入前端组件的问题,webpack配置需要指定target为node。
且服务端不太需要路由分隔,客户端则需要且带hash。
另外客户端需要混淆最小化静态文件代码。
且两端打包入口及出口均不同。
客户端需要打包引入的第三方包,而服务端打包则可以将其排除掉。
node端怎么加载前端组件的?
node环境既不支持jsx也不支持es module。是通过babel、webpack吗?如果是,怎么打包,是只打包前端组件还是说连nodejs一起打包?
如果是前端和node一起打包,由于引入babel,会导致加载模块数量变得巨大,而且不方便调试。
所以最好的方式是只处理前端组件。
通过webpack的配置,设置target为node。
通过webpack的配置,设置externals,来排除对node_modules的打包,将范围限制在前端组件部分。
组件在客户端和服务端分别怎么获取数据?
如何在客户端切换路由时,获取组件数据。 next.js是魔改react-router,⾃⼰封装了了⼀套router,监听你的各种路路由跳转动作。
可以通过封装高阶组件笔记内容
默认从全局变量里拿数据,在客户端切换路由,或者csr模式情况下刷新页面的时候,就走fetch拿远程数据。
const fetch = async (WrappedComponent: FC, dispatch: React.Dispatch<Action>, props: RouteComponentProps) => {
//执行请求方法,并拿到结果返回
const asyncData = WrappedComponent.fetch ? await WrappedComponent.fetch(props) : {}
await dispatch({
type: 'updateContext',
payload: asyncData
})
}
// HOC
// 用于在路由切换和csr模式下通过fetch拿到数据给客户端组件
function wrapComponent (WrappedComponent: FC) {
return withRouter(props => {
const { dispatch } = useContext(window.STORE_CONTEXT)
useEffect(() => {
didMount()
}, [])
const didMount = async () => {
if (routerChanged || !window.__USE_SSR__) {
// ssr 情况下只有路由切换的时候才需要调用 fetch
// csr 情况首次访问页面也需要调用 fetch
// 调用fetch
await fetch(WrappedComponent, dispatch, props)
}
if (!routerChanged) {
// routerChanged 为 true 代表已经进行过切换路由的操作
routerChanged = true
}
}
return <WrappedComponent {...props}></WrappedComponent>
})
}
服务端则是在服务端直接fetch拿到数据,如果是csr则不渲染组件,只给客户端去渲染即可。笔记内容
Next服务端渲染和同构的原理是什么?
这里以react的框架next为例。
getInitialProps()能够在服务端运行,也能够在client运行。当页面第一次加载时,服务器收到请求,getInitialProps()会执行,getInitialProps()返回的数据,会序列化后添加到 window.__NEXT_DATA__.props上,写入HTML源码里,类似于<script>window.__NEXT_DATA__={props:{xxx}}</script>。
这样服务端的getInitialProps()就实现了把数据传送给了客户端。
客户端的收到了HTML源码,有了数据,想做什么都可以。比如可以拿着window.__NEXT_DATA__.props的数据来初始化React组件的props属性。
具体过程如下: 当页面是用户通过超链接跳转过去,而不是用户输入网址或刷新来访问的,这时候是纯客户端的行为,没有HTTP请求发出去。用户如果通过超链接跳转回这个页面,客户端的getInitialProps()开始起作用了,它会自动读取HTML源码里 window.NEXT_DATA.props里的数据并作为React组件的props。
怎么降级为客户端渲染?
每次打包两端的代码。
通过url参数csr来进行标识,服务端不再渲染组件。
<StaticRouter>
<Context.Provider value={{ state: fetchData }}>
<Layout ctx={ctx} config={config} staticList={staticList}>
{/* //如果是csr模式,则服务端不渲染组件 */}
{isCsr ? <></> : <Component />}
</Layout>
</Context.Provider>
</StaticRouter>
而客户端需要手动去fetch数据,而不是等服务端给过来:
// HOC
// 用于在路由切换和csr模式下通过fetch拿到数据给客户端组件
function wrapComponent (WrappedComponent: FC) {
return withRouter(props => {
const { dispatch } = useContext(window.STORE_CONTEXT)
//利用useEffect只在客户端执行
useEffect(() => {
didMount()
}, [])
const didMount = async () => {
if (routerChanged || !window.__USE_SSR__) {
// ssr 情况下只有路由切换的时候才需要调用 fetch
// csr 情况首次访问页面也需要调用 fetch
// 调用fetch
await fetch(WrappedComponent, dispatch, props)
}
if (!routerChanged) {
// routerChanged 为 true 代表已经进行过切换路由的操作
routerChanged = true
}
}
return <WrappedComponent {...props}></WrappedComponent>
})
}
什么节点降级为CSR最合适?
降级的同时,还需要保证启动可以通过csr来完成。这样方便ssr挂掉时迅速用csr启动来补位。
至于怎么补位,可以通过每次启动ssr、csr两个service,然后nginx去探活,如果ssr的service挂了,就去访问csr的service。
服务端路由和客户端路由在处理上有什么区别?
以react-router为例,服务端路由需要用StaticRouter,客户端需要用BrowserRouter。
因为服务器端渲染是一种无状态的渲染。将服务器上接收到的URL传递给StaticRouter路由用来匹配,同时支持传入context特性。当在浏览器上渲染一个<Redirect>时,浏览器历史记录会改变状态,同时将屏幕更新。在静态的服务器环境中,无法直接更改应用程序的状态。在这种情况下,可以在context特性中标记要渲染的结果。如果出现了context.url,就说明应用程序需要重定向。从服务器端发送一个恰当的重定向链接即可。
而BrowserRouter则是通过history API来管理的客户端路由。所以a标签的都是走的SSR,而自由pushState的才会走CSR。
总体来看就是在服务端通过redirect来跳转走SSR,客户端通过pushState来跳转走CSR。
参考:
如何高效稳定的部署
打通serverless
使用阿里云和腾讯云等平台,将打包的文件部署
云函数的yml如下所示:
service:
name: serverless-ssr
provider:
name: aliyun
aggregation: # 聚合成一个函数发布
ssr: # 聚合函数的名称
deployOrigin: false
functionsPattern:
- '*'
package:
include:
- build
exclude:
- package-lock.json
artifact: code.zip
deployType: egg ## 部署的应用类型
有做过哪些SSR性能方面的优化?
1、缓存
一般分为页面级别缓存和组件级别缓存.
页面级别缓存: 对于相同的页面的请求, 其内容也相同(不考虑个性化页面情况), 所以将路由与对应页面缓存下来可以很有效命中缓存, 降低性能开销.
// 使用 LRU
const microCache = LRU({
max: 100,
maxAge: 1000 // 重要提示:条目在 1 秒后过期。
})
...
// 命中缓存
const hit = microCache.get(req.url)
if (hit) {
return res.end(hit)
}
...
// 缓存下来
microCache.set(req.url, html)
组件缓存在组件渲染过程进行命中判断, 所以会影响组件渲染结果, 所以要确保组件不依赖上下文状态且无副作用, 换句话说缓存的是不会改变内容的展示型组件。
2、优化异步
将各个promise通过合并到promise.all再await来解决。
}, 'coursedetail');
});
- // 获取用户登陆信息
- await store.dispatch(userCenterFetch())
- await store.dispatch(fetchLoginInfo())
+ // // 获取用户登陆信息
+ // await store.dispatch(userCenterFetch())
+ // await store.dispatch(fetchLoginInfo())
+ let fromItemId = ''
const courseState = store.getState().course
const courseInfo = courseState.course.baseCourseInfo
const courseId = courseInfo ? `${courseInfo.courseId}` : null;
}
if (!courseId || courseId !== params.courseid) {
if (query.fromCourseId) {
- await store.dispatch(courseFetch(params.courseid, query.fromCourseId))
+ // await store.dispatch(courseFetch(params.courseid, query.fromCourseId))
+ fromItemId = query.fromCourseId
} else if (query.fromItemId) {
// 续费课详情页接口
- await store.dispatch(courseFetch(params.courseid, query.fromItemId))
+ // await store.dispatch(courseFetch(params.courseid, query.fromItemId))
+ fromItemId = query.fromItemId
} else {
- await store.dispatch(courseFetch(params.courseid))
+ // await store.dispatch(courseFetch(params.courseid))
+ fromItemId = ''
}
}
+
+ await Promise.all([
+ // 获取用户登陆信息
+ store.dispatch(userCenterFetch()),
+ store.dispatch(fetchLoginInfo()),
+ store.dispatch(courseFetch(params.courseid, fromItemId))
+ ])
+
const dialogShow = courseState.dialog.willShow
if (dialogShow && courseId !== params.courseid) { // 调到其他课程需要干掉弹窗
await store.dispatch(hideCourseDialog())
参考
3、SSR相关渲染链路使用最合适的API
比如在服务端渲染react组件为html时,可以使用renderToNodeStream通过stream的方式来优化,再降级为renderToString。参考:笔记内容,就是vue也提供了一样的api:笔记内容
在客户端,如果是全客户端渲染则通过react dom的render来渲染组件,如果是注水模式,则通过react dom 的hydrate来注水,从而只增加事件绑定,而不是完全渲染。参考:笔记内容
可视化搭建CMS
编辑预览区域怎么做?
通过iframe进行样式和逻辑的隔离,通过postmessage进行通信
或者通过react的renderToSting、vue的renderToString等方法进行预览,配合shadow dom进行隔离。
模块组件的最佳配置
模块组件的模块信息和需要用户填入的信息json遥相呼应。 其中将模块组件和交互组件进行分割,同一个模块可以选择不同的交互形式,从而得到不同的交互组合效果。比如分页+卡片A/下拉更多+卡片B等等。
{
"chineseName" : "轮播图组件",
"content" : "<ux-cms-vue-slider list={list}></ux-cms-vue-slider>",
"dataTemplate" : "c2_vue_slider",
"dependence" : "pool/component-cms/src/vue-slider/web/ui",
"description" : "轮播图组件",
"name" : "m_vue_slider",
"previewImg" : "//edu-image.nosdn.127.net/24d973af6c7d4acd9f7307955e2a535b.jpg?imageView&quality=100",
"style" : "",
"type" : 1,
"viewType" : 1,
"cdn": "vue,swiperCss,swiperJs,vueAwesomeSwiper"
}
如何兼容多技术栈
每个页面模板可以自由组合头部和底部初始化模块,整个页面为ftl。可视化编辑仅仅决定中间部分的模块。即使如此,各模块也有一个cdn参数提供,用于引入各自需要的独特资源,在打工时统一去重加载。
不同的页面怎么设计插件化
不同页面模块的内容由插件定制组装而成,插件有:
分享插件、数据埋点插件、导航插件、SSR插件、异常监控插件、ABTest插件等等。
插件参考webpack使用tapable,在页面不同的生命周期进行不同的钩子处理。
具体插件功能
数据插件
写一段 js 脚本,前端通过 script 标签引入这段 js;
通过页面的用户行为,触发相应 js 事件,并拿到数据;
通过请求 nginx 上某一个静态资源的形式,将数据进行拼接发送到 nginx;
nginx 产生一条日志,云端拿到数据进行清洗、分析
可视化圈选埋点,通俗的讲就是无需开发者在代码中加入埋点逻辑代码,只需要通过 UI 点点点的方式就能埋好一个点,有效避免了埋点代码污染问题。被点击到的 dom 元素都赋予唯一标识,这里采用 dom 元素唯一的 xpath 当作唯一标识。说白了,可视化圈选埋点就是制定一套规则,云端利用这套规则去海量的数据里清洗出需要的数据,而规则中就包含了 xpath。
仅仅web端的话通过css选择器也可以,网易哈勃基于此
导航插件
支持各种切换方式,如上下滚动、左右tab切换等等。
SSR插件
整体逻辑变为SSR模式,不再是CSR打包结果集合。
ABTest插件
在专题后台录入两套不同的组件。分别是A和B组。每个组会自己的起始值和终止值如 0-5 6-10.
然后页面初始化时会生成一个随机数在这个区间之内,比如说8,并记录到cookie中。cookie名带上专题的key。
这样这个用户对于这个专题就永远走到b组件了。
如何让开发去中心化
通过scope包对不同团队不同插件进行npm包区分管理。
如何保证性能?
每次制作完成,上线或准备就绪,都会通知lighthouse-apm 对页面进行性能评估,并发送邮件给相关负责人,影响到对应前端的相关绩效分数。
模块组件懒加载
模块怎么开发?
提供cli统一开发模块组件,并上报内容等等。模块缩略图由本地puppeteer对应的demo来生成,确保本地demo可启动。
模块间怎么通信?
通过全局规约发布订阅消息总线来完成跨模块的通信
那些数据大盘建设?
模块组件使用计算、各个营销活动打点计数、自动化埋点点击区域热图显示等等,ABtest效果展示。
截屏服务
截屏服务一般是由node来提供,将用户屏幕内容截取。
需要什么参数
await screenShotService.shotSingle({
url: url as string,
fullPage: fullPage === 'true',
outputPath,
userAgent: userAgent as string,
viewPort: {
width: Number(viewPortWidth),
height: Number(viewPortHeight),
},
scrollLoad: scrollLoad === 'true',
})
const stats = fs.statSync(outputPath)
截图过程
const shotSingle = async (options:ScreenShotOption) => {
const {
url, userAgent, viewPort, outputPath, fullPage, scrollLoad,
} = { ...defaultOption, ...options }
const { page, browser } = await preparePage({ userAgent, viewPort })
await page.goto(url, {
timeout: TIME_OUT,
waitUntil: 'networkidle2',
})
if (scrollLoad) {
await autoScroll(page)
}
await page.screenshot({
path: outputPath,
fullPage,
})
await browser.close()
}
怎么模拟页面
使用puppeteer来启动页面,设置viewport、ua等等
export const preparePage = async (options:PageOption): Promise<PageReturn> => {
const {
userAgent, viewPort,
} = options || {}
const ua = userAgent || MOBILE_UA
const dpr = ua.toLocaleLowerCase().includes('mobile') ? 2 : 1
const browser = await puppeteer.launch({
headless: true,
// linux环境一定不能省略下面俩个参数 noSandbox 还有disableSetuidSandbox, 否则会运行失败!!!
args: ['--no-sandbox', '--disable-setuid-sandbox'],
})
const page = await browser.newPage()
await page.setUserAgent(ua)
await page.setViewport({
width: viewPort?.width || VIEW_PORT.width,
height: viewPort?.height || VIEW_PORT.height,
deviceScaleFactor: dpr,
})
return {
browser,
page,
}
}
怎么滚屏
通过go到了指定url页面后需要进行滚屏
/**
* 自动滚动到底,注意;必须可滚动到底
*/
async function autoScroll(page:Page) {
await page.evaluate(`(async () => {
await new Promise((resolve) => {
// 页面的当前高度
let totalHeight = 0
// 每次向下滚动的距离
const distance = 100
// 通过setInterval循环执行
const timer = setInterval(() => {
const { scrollHeight } = document.body
// 执行滚动操作
window.scrollBy(0, distance)
// 如果滚动的距离大于当前元素高度则停止执行
totalHeight += distance
if (totalHeight >= scrollHeight) {
clearInterval(timer)
resolve()
}
}, 100)
})
})()`)
}
怎么截屏
截屏并关闭页面即可。
await page.screenshot({
path: outputPath,
fullPage,
})
await browser.close()
其他
怎么实现草稿,多终端同步,以及冲突问题
草稿和正式资源的区别无非在于多存储一份。
至于多终端同步,则是在多端都用相同接口即可。
如果需要考虑多人协作的冲突问题,则需要引入版本的概念,在保存定档后进行编辑的版本,对不同人的操作,进行diff算法,并将冲突内容显示出来,问题解决后,再定为下一个版本。
具体的版本管理方式可以采用乐观锁的方式。
举一个乐观锁版本的简单例子:
假设数据库中帐户信息表中有一个 version 字段,当前值为 1 ;而当前帐户余额字段( balance )为 $100 。
操作员 A 此时将其读出( version=1 ),并从其帐户余额中扣除 $50( $100-$50 )。
在操作员 A 操作的过程中,操作员B 也读入此用户信息( version=1 ),并从其帐户余额中扣除 $20 ( $100-$20 )。
操作员 A 完成了修改工作,将数据版本号加一( version=2 ),连同帐户扣除后余额( balance=$50 ),提交至数据库更新,此时由于提交数据版本大于数据库记录当前版本,数据被更新,数据库记录 version 更新为 2 。
操作员 B 完成了操作,也将版本号加一( version=2 )试图向数据库提交数据( balance=$80 ),但此时比对数据库记录版本时发现,操作员 B 提交的数据版本号为 2 ,数据库记录当前版本也为 2 ,不满足 “ 提交版本必须大于记录当前版本才能执行更新 “ 的乐观锁策略,因此,操作员 B 的提交被驳回。
这样,就避免了操作员 B 用基于 version=1 的旧数据修改的结果覆盖操作员A 的操作结果的可能。
至于针对文件内容的diff,可以使用git的diff,myers算法,其原理可以参考git的diff操作是基于什么算法的(myers)?简单说下原理。
参考:
简单介绍下怎么实现一套前端水印系统
明水印的生成方式主要可以归为两类,一种是 纯 html 元素(纯div),另一种则为背景图(canvas/svg)。
div实现的话,可以通过shadow dom来隔离和优化性能,通过mutationObserver来防止删除。
canvas的实现很简单,主要是利用canvas 绘制一个水印,然后将它转化为 base64 的图片,通过canvas.toDataURL() 来拿到文件流的 url , 然后将获取的 url 填充在一个元素的背景中,然后我们设置背景图片的属性为重复。
一个业界比较好的明水印实现:watermark-dom源码分析
明水印的破解方案为:
如果没有MutationObserver,则直接删除;
如果有MutationObserver,可以先通过浏览器设置disable javascript再控制台手动delete dom;
或者复制一个 body 元素,然后将原来 body 元素的删除;
或者直接通过charles拦截将水印相关的逻辑去除。
暗水印是指一种肉眼不可见的水印方式,可以保持图片美观的同时,保护你的资源版权。通过微小的改动RGB,RGB 分量值的小量变动,是肉眼无法分辨的,不影响对图片的识别。
配合加密解密算法来完成用户的识别。
实例demo可以参考:pageDemo/blackWater at main · FunnyLiu/pageDemo
参考:
从破解某设计网站谈前端水印(详细教程) - 前端开发博客 - OSCHINA - 中文开源技术交流社区
不能说的秘密——前端也能玩的图片隐写术 | AlloyTeam
设计一套插件系统,或者说业界的插件系统都是基于什么方案模式的?
首先了解是否写过-plugin?简单描述一下编写-plugin-的思路?,和有没有写过babel插件,是什么模式解析的?,vue-use使用插件,是如何实现的?。
webpack的基于tapable完成一套有序的可拓展的事件系统,也就是发布订阅模式;
babel是基于访问者模式,来隔离对AST的直接遍历;
egg是基于事件完成生命周期的通知,和通过规约拿到原型注入;
vue是简单的注入原型。
自建图标库怎么建设的,原理是什么?
核心原理就是把svg转成字体文件。主要是通过gulp-iconfont这个库来完成的。
整个系统可以参考bolin-L/nicon: 字体图标管理平台 http://icon.bolin.site/#/。
<span class="icon-qq"></span>
<style>
@font-face {
font-family: "hello";
src: url('//at.alicdn.com/t/font_1475388520_7015634.ttf') format('truetype')
}
.icon-qq:before { font-family:"hello";content: "\e600"; }
</style>
通过字体和伪类遥相呼应。辅助性的装饰性的内容使用伪类,不写进html的内容中,就不影响语义。
- 字体文件(svg/ttf/woff)包含内容:一个Unicode码对应一个图形(即字体图标)
- 用
@font-face给字体文件取名,让元素使用我们自定义的字体 - 伪元素的content用图标的unicode码,就展示字体文件中该unicode对应的图形
在dom上增加一个伪元素,css中正斜杠\表示一个16进制数字。这样写的好处是可以直接通过审查dom元素就知道它引用的是哪个字形,看起来更加语义化。
node怎么做绘图?
生成证书图片等服务一般是用node来完成,这里整理下实现。
1、通过模板和数据,组装canvas实例。
这里的 Canvas来自node-canvas这个库
// 渲染
async render(temp, data){
// 处理模板数据
temp = super._formatTemplate(temp, data);
let w = temp.canvasProperty.width || 1000, h = temp.canvasProperty.height || 1000;
let pw = temp.canvasProperty.printWidth || 297, ph = temp.canvasProperty.printHeight || 210; // 打印尺寸,单位毫米
let scale = renderUtil.getRenderScale(pw, ph);
// log.debug('证书渲染尺寸:' + scale.scaleW + ' * ' + scale.scaleH);
this._canvasIns = new Canvas(scale.scaleW, scale.scaleH);
let context = this._canvasIns.getContext('2d');
// 缩放
this._scale(context, temp, scale.scaleW / w, scale.scaleH / h);
return this._downloadAllImage(temp).then((imageList) => {
log.debug('证书全部资源下载完成');
return this._renderItemsByOrder(context, temp, imageList); // 要注意先后顺序
})
}
2、针对不同的内容,进行不同的渲染
log.debug('渲染背景');
this._renderBackground(context, item.areaProperty);
// 可能同时有图片和文本,一般先渲染图片
if(item.image){
// log.debug('渲染图片');
this._renderImage(context, item.image, item.areaProperty, imageMap);
}
if(item.text){
// log.debug('渲染文本');
this._renderText(context, item.text, item.areaProperty);
}
渲染背景:
// 绘制背景
_renderBackground(context, areaProperty){
/*
边框暂时没做
borderStyle
borderColor
borderWidth
*/
// 如果有背景色
if(areaProperty.backgroundColor){
context.fillStyle = areaProperty.backgroundColor;
context.fillRect(areaProperty.left || 0, areaProperty.top || 0, areaProperty.width || 0, areaProperty.height || 0);
}
}
渲染图片、渲染文字等等,均是使用canvas的api来完成渲染。
使用node搭建过哪些服务?
1、可视化cms
用来做页面生成器的工具
参考可视化搭建cms
2、截屏服务
用来截取用户当前屏幕内容,基于puppeteer
参考截屏服务
3、绘图服务
用来根据用户参数,绘制图片,基于node-canvas
4、SSR
SSR用来优化性能和SEO。
参考ssr
5、性能监控平台
基于lighthouse来做APM平台,给页面自动化打分。
6、图标库
内部图标库,类似iconfont-阿里巴巴矢量图标库
7、内部后台系统
基于egg、nest、koa等等搭建内部后台表单系统。
8、投放系统
基于koa大家外投api系统,接入第三方sdk完成投放上报。
9、微信管理系统
基于微信api,管理微信服务号公综号相关系统。
微信相关
了解微信小程序开发么,能说一说么,和常规的Hybrid有什么区别吗
参考官方文档:小程序简介 | 微信开放文档
网页开发渲染线程和脚本线程是互斥的,这也是为什么长时间的脚本运行可能会导致页面失去响应,而在小程序中,二者是分开的,分别运行在不同的线程中。网页开发者可以使用到各种浏览器暴露出来的 DOM API,进行 DOM 选中和操作。而如上文所述,小程序的逻辑层和渲染层是分开的,逻辑层运行在 JSCore 中,并没有一个完整浏览器对象,因而缺少相关的DOM API和BOM API。
小程序的优势是什么?
无需下载安装,直接使用,运行速度快,项目搭建迅速,短小精悍,每个app源代码不超过2mb
小程序的页面构成?
Index.js index.json index.wxml index.wxss
小程序的生命周期?
Onload onready onshow onhide onunload
Onpulldownrefresh onreachbottom onshareappmessage
简单描述下小程序的原理
微信小程序采用 JavaScript、WXML、WXSS 三种技术进行开发,本质就是一个单页面应用,所有的页面渲染和事件处理,都在一个页面内进行,但又可以通过微信客户端调用原生的各种接口
微信小程序的架构,是数据驱动的架构模式,它的 UI 和数据是分离的,所有的页面更新,都需要通过对数据的更改来实现
小程序分为两个部分 webview和 appService 。其中 webview 主要用来展现UI ,appService 有来处理业务逻辑、数据及接口调用。它们在两个进程中运行,通过系统层 JSBridge 实现通信,实现 UI 的渲染、事件的处理
参考:
详细介绍下小程序的双线程架构
程序的逻辑层与渲染层分开在不同的线程运行,这跟传统的 Web 单线程模型有很大的不同。小程序的渲染层和逻辑层分别由2个线程管理:渲染层的界面使用了 WebView 进行渲染;逻辑层采用 JsCore 线程运行JS脚本。一个小程序存在多个界面,所以渲染层存在多个 WebView 线程,这两个线程的通信会经由微信客户端(下文中也会采用 Native 来代指微信客户端)做中转,逻辑层发送网络请求也经由 Native 转发。
逻辑层和视图层必须通过 Native 层通信。逻辑层和视图层之间的工作方式为:数据变更通过 setData 驱动视图更新;视图层交互触发事件,然后触发逻辑层的事件响应函数,函数中修改数据再次触发视图更新。
小程序使用双线程架构的原因?
为什么采用双线程架构?可能是出于以下原因:
安全可控,沙箱隔离,限制 DOM 和 BOM 能力
不允许跳转至其他网页; 不允许直接操作 DOM; 不允许随意使用 window 上的某些未知的可能有危险的 API;
性能
在浏览器网页中,虽然 JS 执行和 UI 渲染也是处于两个线程,但是 JS 线程和 UI 线程是互斥的(之所以设计为互斥的主要是 JS 可以操作 DOM,所以必须设计为互斥的才能避免二者的不同步问题); 在小程序中,逻辑层和渲染层是独立的,二者不会互相阻塞,因此性能更优(小程序限制了 JS 操作 DOM 的能力,因此不用担心二者的不同步问题);
提供原生渲染能力和原生 API 能力;
各种小程序框架的原理,比如taro、uniapp等
虽然各框架的具体实现不一样,采用的开发语言不一样,但是大体讲,小程序框架所做的工作无非就是两个阶段的处理:编译阶段、运行阶段。
简单来说,这些框架的大致原理就是:
编译阶段:将其他 DSL 转换为符合小程序语法的 WXML、WXSS、JS、JSON;
运行阶段:数据、事件、生命周期等部分的处理和对接;
mpvue
在 Vue 的基础上,mpvue 主要做了以下改造:
编译阶段:修改 vue-template-compiler,将 Vue 代码转换为符合小程序语法规范的 WXML、WXSS; 运行阶段:初始化 Vue 组件实例的同时,初始化小程序页面实例;组件 patch 更新阶段,不再直接操作DOM,而是调用小程序页面实例的 setData 方法将视图更新;此外,还包括生命周期的处理、事件的处理等
uniapp
uniapp 在初期借鉴了mpvue,早期版本实现原理和 mpvue 基本一致。mpvue 的实现,总的来说是将 Vue 实例和小程序页面实例简单粗暴地做了关联,以达到使用 Vue 开发小程序的目的。mpvue 的思路是很好的,但是,mpvue 并没有做深入优化,性能一般。同时,由于 mpvue 后续基本处于无人维护状态,因此无法跟上微信小程序的技术更新(比如自定义组件、分享朋友圈功能)。uniapp 则在 mpvue 的基础上,做了很多的性能优化,也有团队维护。因此新项目基本不推荐采用 mpvue 开发了,更推荐采用 uniapp。
taro
Taro 架构同样分为:编译时和运行时。编译时主要是将 Taro 代码通过 Babel 转换成 小程序的代码,如:JS、WXML、WXSS、JSON。运行时主要是进行一些:生命周期、事件、data 等部分的处理和对接
如何提高小程序的首屏加载时间
提前请求:异步数据数据请求不需要等待页面渲染完成
利用缓存:利用storage API对异步请求数据进行缓存,二次启动时先利用缓存数据渲染页面,再进行后台更新
避免白屏:先展示页面骨架和基础内容
及时反馈:及时地对需要用户等待的交互操作给出反馈,避免用户以为小程序没有响应
性能优化:避免不当使用setdata和onpagescroll
微前端
有没有了解过微前端,谈谈实现思路?
微前端本身就是集合大多数不同技术栈的前端项目。
做的好的有single-spa,通过路由来激活不同的项目,再接上不同项目的自己的子路由系统。但是并没有做应用隔离。
阿里出品的qiankun,路由方面依赖了single-spa,应用隔离使用了jsSandbox的思想。 jsSandbox就是隔离js运行时环境,举个例子,我们可以对window创建一个全局代理:
const p = new Proxy(window,{});
然后让js 的执行上下文变成p:
(function(){}).bind(p);
这时候的p就是一个沙箱。
参考:
目前几个微前端框架的优缺点说一下
qiankun 方案
qiankun 方案是基于 single-spa 的微前端方案。
特点
- html entry 的方式引入子应用,相比 js entry 极大的降低了应用改造的成本;
- 完备的沙箱方案,js 沙箱做了 SnapshotSandbox、LegacySandbox、ProxySandbox 三套渐进增强方案,css 沙箱做了 strictStyleIsolation、experimentalStyleIsolation 两套适用不同场景的方案;
- 做了静态资源预加载能力;
不足
- 适配成本比较高,工程化、生命周期、静态资源路径、路由等都要做一系列的适配工作;
- css 沙箱采用严格隔离会有各种问题,js 沙箱在某些场景下执行性能下降严重;
- 无法同时激活多个子应用,也不支持子应用保活;
- 无法支持 vite 等 esmodule 脚本运行;
micro-app 方案
micro-app 是基于 webcomponent + qiankun sandbox 的微前端方案。
特点
- 使用 webcomponet 加载子应用相比 single-spa 这种注册监听方案更加优雅;
- 复用经过大量项目验证过 qiankun 的沙箱机制也使得框架更加可靠;
- 组件式的 api 更加符合使用习惯,支持子应用保活;
- 降低子应用改造的成本,提供静态资源预加载能力;
不足
- ~接入成本较 qiankun 有所降低,但是路由依然存在依赖;~(虚拟路由已解决)
- ~多应用激活后无法保持各子应用的路由状态,刷新后全部丢失;~(虚拟路由已解决)
- css 沙箱依然无法绝对的隔离,js 沙箱做全局变量查找缓存,性能有所优化;
- 支持 vite 运行,但必须使用 plugin 改造子应用,且 js 代码没办法做沙箱隔离;
- 对于不支持 webcompnent 的浏览器没有做降级处理;
EMP 方案
EMP 方案是基于 webpack 5 module federation 的微前端方案。
特点
- webpack 联邦编译可以保证所有子应用依赖解耦;
- 应用间去中心化的调用、共享模块;
- 模块远程 ts 支持;
不足
- 对 webpack 强依赖,老旧项目不友好;
- 没有有效的 css 沙箱和 js 沙箱,需要靠用户自觉;
- 子应用保活、多应用激活无法实现;
- 主、子应用的路由可能发生冲突;
无界 方案
基于web component 和 ifram的微前端方案
特点
- 接入成本是最低的了
不足
- 基于iframe,内存占用和通信带来额外问题
- 使用量少,问题暴露较少
参考:
乾坤框架怎么实现的沙盒机制?
针对 javascript:
qiankun 沙箱的实现里,我们会有两个环境:一个代表的是外部的部分,就是我们的全局环境 Global Env,指的是你框架应用所运行的全局环境。而子应用加载的时候,实际上是应该跑在一个内部的沙箱环境里面。
沙箱实现思路有两条:其中最经典的实践思路其实是快照沙箱。
快照沙箱就是在应用沙箱挂载和卸载的时候记录快照,在应用切换的时候依据快照恢复环境
快照怎么打?其实也有两种思路:
一种是直接用 windows diff。把当前的环境和原来的环境做一个比较,我们跑两个循环,把两个环境作一次比较,然后去全量地恢复回原来的环境。
另一种思路其实是借助 ES6 的 proxy 就是代理。通过劫持 window ,我们可以劫持到子应用对全局环境的一些修改。当子应用往 window 上挂东西、修改东西和删除东西的时候,我们可以把这个操作记录下来。当我们恢复回外面的全局环境的时候,我们只需要反向执行之前的操作即可。比如我们在沙箱内部设了一个新的变量 window.a = 123 。那在离开的时候,我们只需要把 a 变量删了即可。
快照沙箱这个思路也正是 qiankun1.0 所使用的思路,它相对完善,但是缺点在于无法支持多个实例,也就是说我两个沙箱不可能同时激活,我不能同时挂载两个应用,不然的话这两个沙箱之间会打架,导致错误。
所以说我们把目光又投向了另一条思路,我们让子应用里面的环境和外面的环境完全隔离。就如图所示,我们的 A 应用就活在 A 应用的沙箱里面,B 应用就活在 B 应用的沙箱里面,两者之间要不发生干扰,这个沙箱的实现思路其实也是通过 ES6 的 proxy,也通过代理特性实现的。
针对css:
qiankun 所做的第一件事情其实是动态样式表。当你从子应用 A 切换到子应用 B 的时候,这个时候需要把子应用的样式表 A 的样式给删除,把子应用 B 的样式表给挂载。这样就避免了子应用 A 的样式和子应用 B 的样式同时存在于这个项目中,就做到了最基本的隔离。
来到 qiankun2.0 之后,我们追加了一个新的选项,叫作严格样式隔离,其实严格样是隔离代表 Shadow DOM。Shadow DOM 是可以真正的做到 CSS 之间完全隔离的。
参考:
乾坤框架子应用间如何通信的?
基于URL:
其实有一种最朴素的通讯方案,就是基于 URL。前端有一种设计叫做 URL 中心设计,就是说你的 URL 完全决定了你页面展示出来是什么样子。
假如我的应用里有一个列表,有一个分页,当你点下一页的时候,是不是就产生了一个在第二页的 query 参数?你可能会把这个参数同步到路由上,这样你把这个链接分享给别人的时候,别人就能看到跟你一样的页面。
我们其实完全可以把这种路由翻译成看作是一个函数调用,比如说这里的路由 b/function-log,query 参数 data 是 aaa ,我们可以把这个路由 URL 理解为我在调用 B 应用的 log 函数,这就像一次函数调用一样。当我们从应用 A 跳去应用 B,对应路由发生变化的时候,就是触发了一次函数调用,触发了一次通信。
所以路由实际上也有通信的功能。这种通信方式是完全解耦的,但是缺点就是比较弱。
基于发布订阅:
另一种应用间通信的模型就是我们可以挂一个事件总线。应用之间不直接相互交互,我都统一去事件总线上注册事件、监听事件,通过这么一个发布订阅模型来做到应用之间的相互通信。
有趣的是,我们什么框架都不需要引入,什么第三方库都不需要引入,这里我们有一个天然的事件总线:window 的 CustomEvent 。我们可以在 window 上监听一个自定义事件,然后在任意地方派发一个自定义事件,我们可以天然的通过自定义事件来做到应用之间相互通信。
基于props:
qiankun 本身在 2.0 的时候提供了最简单的基于 props 通信的 API。
在我们提供 API 之前,就有非常多的同学来问我们应该应用和应用之间怎么通信?我们当时都没有给出具体的解决方案,给出具体的 API 或者给出具体的实践和引导。实际上在你的应用需求、复杂度不同的时候,你应该相应的自己挑选自己适合的应用间通信方案。
参考:
使用qiankun的过程中,遇到哪些坑?
1、主从应用之间样式不隔离。
默认情况下沙箱可以确保单实例场景子应用之间的样式隔离,但是无法确保主应用跟子应用、或者多实例场景的子应用样式隔离。当配置为 { strictStyleIsolation: true } 时表示开启严格的样式隔离模式。这种模式下 qiankun 会为每个微应用的容器包裹上一个 shadow dom 节点,从而确保微应用的样式不会对全局造成影响。
在最新的 qiankun 版本中,你也可以尝试通过配置 { sandbox : { experimentalStyleIsolation: true } } 的方式开启运行时的 scoped css 功能,从而解决应用间的样式隔离问题。 PS:目前该特性还处于实验阶段,如果碰到一些问题欢迎提 issue 来帮助我们一起改善。
路由级别的微前端有哪些难点?
包括路由的处理、应用加载的处理和应用入口的选择
路由处理
在 qiankun 这里,我们就直接选用了社区成熟的方案 Single-SPA。Single-SPA 已经劫持的路由,帮我们做好了加载这件事情,也帮我们做好了路由切换这件事情,在这个方面我们就没有自己造轮子了。
首先我们来看应用路由的问题。在微前端体系结构下,路由的划分往往是如图这个样子的,这也是一种比较简单的方案。
我们主应用加载了应用 A 和应用 B。这个时候对于主应用来讲,我就有两个路由 /a/* 和 /b/* 。在路由 A 下我会加载应用 A,在另一个路由 B 下加载应用 B。
那当我在路由 /b/list 下重刷页面的时候会发生什么过程?实际上我需要先加载我的主应用,我的主应用检测到这是一个 /b/ 打头的路由,于是它知道我应该去加载应用 B,随后去加载了应用 B。到了此时应用 B 接管了路由,它发现后面的路由是 /list ,于是它显示出 /list 的正确页面,总体上就是这么一个过程。
应用加载的处理
什么样的一个应用能够成为子应用,能够接入到我们的框架应用里?由于我们需要技术栈无关,所以我们希望接入是一个 协议接入。只要你的应用实现了 bootstrap 、mount 和 unmount 三个生命周期钩子,有这三个函数导出,我们的框架应用就可以知道如何加载这个子应用
这三个钩子也正好是子应用的生命周期钩子。当子应用第一次挂载的时候,我们会执行 bootstrap 做一些初始化,然后执行 mount 将它挂载。如果你是一个 React 技术栈的子应用,你可能就在 mount 里面写 ReactDOM.render ,把你的 ReactNode 挂载到真实的节点上,把应用渲染出来。当你应用切换走的时候,我们会执行 unmount 把应用卸载掉,当它再次回来的时候(典型场景:你从应用 A 跳到应用 B,过了一会儿又跳回了应用 A),这个时候我们是不需要重新执行一次所有的生命周期钩子的,我们不需要从 bootstrap 开始,我们会直接从 mount 阶段继续,这就也做到了应用的缓存。
应用入口的选择
qiankun 的第一选择其实是 HTML 入口,就是提供一份 HTML 文件。因为这份 HTML 中其实包含了子应用的所有信息。它包含网页的结构,包含了一些元信息。大家可以看到在这份 HTML 里我们有 CSS、JS 链接、有应用要挂载的根路由 root 的 DOM。这些信息是非常全面的,比单纯你拿 JS 和 CSS 组成一份资源列表作为入口,要清晰和完整得多。同时 HTML Entry 这样的设计,也使得我们在接入一些老旧应用的时候,更加简单。
应用的隔离与通信
js的隔离
qiankun 沙箱的实现里,我们会有两个环境:一个代表的是外部的部分,就是我们的全局环境 Global Env,指的是你框架应用所运行的全局环境。而子应用加载的时候,实际上是应该跑在一个内部的沙箱环境里面。
沙箱实现思路有两条:其中最经典的实践思路其实是快照沙箱。这就是说当我应用挂载了又卸载了,这个过程走了一遍之后,我当前整个 Windows 运行环境恢复成原来的样子,应用内部所做的修改,在它卸载的时候就会被恢复,这是快照沙箱思路。
快照怎么打?其实也有两种思路:
一种是直接用 windows diff。把当前的环境和原来的环境做一个比较,我们跑两个循环,把两个环境作一次比较,然后去全量地恢复回原来的环境。
另一种思路其实是借助 ES6 的 proxy 就是代理。通过劫持 window ,我们可以劫持到子应用对全局环境的一些修改。当子应用往 window 上挂东西、修改东西和删除东西的时候,我们可以把这个操作记录下来。当我们恢复回外面的全局环境的时候,我们只需要反向执行之前的操作即可。
快照沙箱这个思路也正是 qiankun1.0 所使用的思路,它相对完善,但是缺点在于无法支持多个实例,也就是说我两个沙箱不可能同时激活,我不能同时挂载两个应用,不然的话这两个沙箱之间会打架,导致错误。
所以说我们把目光又投向了另一条思路,我们让子应用里面的环境和外面的环境完全隔离。就如图所示,我们的 A 应用就活在 A 应用的沙箱里面,B 应用就活在 B 应用的沙箱里面,两者之间要不发生干扰,这个沙箱的实现思路其实也是通过 ES6 的 proxy,也通过代理特性实现的。
样式隔离
最基本的是规约,类似BEM
工程化手段则是:
当前 css module 其实非常成熟一种做法,就是通过编译生成不冲突的选择器名。你只要把你想要避免冲突的应用,通过 css module (在构建工具里加一些 css 预处理器即可实现)就能很简单的做到。css module 构建打包之后,应用之间的选择器名就不同了,也就不会相互冲突了。
css-in-js 也是一种流行的方案,通过这种方式编码的样式也不会冲突,这几个方案实现起来都不复杂,而且都非常行之有效。所以绝大部分情况下,大家手动用工程化手段处理一下主子应用之间的样式冲突,就可以解决掉样式隔离的问题。
还可以shadom DOM,可是会有一些全局弹框的风险,基本还是工程化方案为主。
应用通信
1、基于url
路由实际上也有通信的功能。这种通信方式是完全解耦的,但是缺点就是比较弱。
2、发布订阅
另一种应用间通信的模型就是我们可以挂一个事件总线。应用之间不直接相互交互,我都统一去事件总线上注册事件、监听事件,通过这么一个发布订阅模型来做到应用之间的相互通信。
有趣的是,我们什么框架都不需要引入,什么第三方库都不需要引入,这里我们有一个天然的事件总线:window 的 CustomEvent 。我们可以在 window 上监听一个自定义事件,然后在任意地方派发一个自定义事件,我们可以天然的通过自定义事件来做到应用之间相互通信。
3、基于prop
我们把 state 和 onGlobalStateChange (就是监听函数),还有我们的 onChange (就是 setGlobalState )三个都传给子应用。我们基于 props 也就可以实现一个简单的主子应用之间通信。
那当我们这样子实现了主子应用之间通信之后,我们子应用与子应用之间通信怎么做?让大家都跟主应用通信就行了。子应用和子应用之间就不要再多加一条通信链路了,我们大家都基于 props 和主应用通信,这样也能解通信问题。
参考:
同一路由下不同dom的微前端怎么解决?
1、简单方案
通过roll 语法树改造,参与原始打包和启动,方便开发
2、通过独立出来,打包为umd、在原始逻辑处注入dom
3、通过动态模块下发系统,sdk json生成html局部渲染。这个可以参考云课堂微前端解决方案文字版。
简单说下云课堂微前端解决方案文字版:
1、前端页面植入SDK。
SDK根据DOM拿到组件的key及版本。如果有版本指定,就直接从crcdn请求请求js。如果没有指定版本,就去后端接口拿到组件可以及环境标识及对应应该加载的版本号,然后回来组装js加载。
2、组件库monorepo,开发各个不同的组件,各组件基于不同的技术栈,最终打包成name_version.js文件。 通过模块组件管理平台的接口,将name_version.js文件,发布到平台内。
3、模块组件管理平台,对模块的基本管理、预览。以及不同模块在不同环境标识下当前使用的版本号进行控制,控制完成后发布,线上即使小。
通信通过全局总线
如何组装大型前端项目模块群
整体思路就是各个不同站点的前端工程其实就是壳,由无数个模块组成,每个模块可以独立启动和进行复用。类似在网易云课堂经历的nej module和大众的atom。
后端也是一样。
vue方案
针对于vue而言,可以通过vue插件的模式,将子module的内容注入到vue的原型中,不论是接口、组件还是state亦或是router。
react方案
暂时无解。暂时思考是umi这种从规约生成真正执行文件的框架过程中可行。在规约步骤中去完成注入,最后生成工程代码。
egg方案
针对egg而言,需要定义一套自己的loader,来实现对其ctx的写入和修改。
nest方案
nest天然支持了module,所以相对会简单,后端暴露独立的module,进行组装即可。
打包工具
前端圈有哪些打包工具?
1、Grunt:最老牌的打包工具,它运用配置的思想来写打包脚本,一切皆配置,所以会出现比较多的配置项,诸如option,src,dest等等。而且不同的插件可能会有自己扩展字段,认知成本高,运用的时候需要明白各种插件的配置规则。
2、Gulp:用代码方式来写打包脚本,并且代码采用流式的写法,只抽象出了gulp.src, gulp.pipe, gulp.dest, gulp.watch 接口,运用相当简单。更易于学习和使用,使用gulp的代码量能比grunt少一半左右。
3、Webpack: 是模块化管理工具和打包工具。通过 loader 的转换,任何形式的资源都可以视作模块,比如 CommonJs 模块、AMD 模块、ES6 模块、CSS、图片等。它可以将许多松散的模块按照依赖和规则打包成符合生产环境部署的前端资源。还可以将按需加载的模块进行代码分隔,等到实际需要的时候再异步加载。它定位是模块打包器,而 Gulp/Grunt 属于构建工具。Webpack 可以代替 Gulp/Grunt 的一些功能,但不是一个职能的工具,可以配合使用。
4、Rollup:下一代 ES6 模块化工具,最大的亮点是利用 ES6 模块设计,利用 tree-shaking生成更简洁、更简单的代码。一般而言,对于应用使用 Webpack,对于类库使用 Rollup;需要代码拆分(Code Splitting),或者很多静态资源需要处理,再或者构建的项目需要引入很多 CommonJS 模块的依赖时,使用 webpack。代码库是基于 ES6 模块,而且希望代码能够被其他人直接使用,使用 Rollup。
5、vite/snowpack等bundleless的打包工具。具体参考vite、snowpack这类bundleless的打包工具是否了解?。开发时通过esmodule和浏览器script type='module'来达到和AMD类似的开发体验,打包时再去进行解析语法树编译之类的流程。
vite、snowpack这类bundleless的打包工具是否了解?
bundleless的理念是减少或避免整个 bundle 的打包,每次保存单个文件时,传统的 JavaScript 构建工具(例如 Webpack 和 Parcel)都需要重新构建和重新打包应用程序的整个 bundle。重新打包时增加了在保存更改和看到更改反映在浏览器之间的时间间隔。在开发过程中, Snowpack 为你的应用程序提供 unbundled server。每个文件只需要构建一次,就可以永久缓存。文件更改时,Snowpack 会重新构建该单个文件。在重新构建每次变更时没有任何的时间浪费,只需要在浏览器中进行 HMR 更新。
vite自己提出相比snowpack的优势是:
Snowpack 的 build 默认是不打包的,好处是可以灵活选择 Rollup、Webpack 等打包工具,坏处就是不同打包工具带来了不同的体验,当前 ESbuild 作为生产环境打包尚不稳定,Rollup 也没有官方支持 Snowpack,不同的工具会产生不同的配置文件;
Vite 支持多 page 打包;
Vite 支持 Library Mode;
Vite 支持 CSS 代码拆分,Snowpack 默认是 CSS in JS;
Vite 优化了异步代码加载;
Vite 支持动态引入 polyfill;
Vite 官方的 legacy mode plugin,可以同时生成 ESM 和 NO ESM;
First Class Vue Support。
综合对比:
Snowpack
缺点:
- 社区不够完善,无法支撑我们后续的业务演进;
- 编译速度提效不明显。
Vite
优点:
- 因其与 rollup 联合,社区里 rolllup 的插件基本都可以直接使用,社区相对完善;
- 编译速度快。
缺点:
- 目前 Vite 处于 2.0 初期,BUG 比较多;
- 本地的 ESbuild 与生产环境的 babel 编译结果差距较大,可能会导致功能差异。
Webpack5
优点:
- 从实际测试要比 Webpack4 快许多;
- 可借助 ESbuild 的代码压缩机制。
缺点:
- 相较 Vite 的本地开发编译速度有写不足(其实算不上缺点,因为解决了生产环境差异)。
参考:
深度分析前端构建工具:Vite2 v.s Snowpack3 v.s. Webpack5 - SegmentFault 思否
bundleless构建时间为什么不随着项目规模增长而增长?
bundleless方案的不会立即编译。
而是,在你访问一个js的时候才去编译它。
bundleless的方案均是依赖esmodule来完成的,esmodule的特性参考esmodule的怎么工作的?,其实esm和amd非常接近可以参考amd和esmodule的区别?。
只不过esm是语法层面支持,可以在静态分析阶段构建依赖图,而AMD不行,需要在运行时。所以esm更快一些。
uglify的原理是什么?
uglify首先是生成了抽象语法树,
接着遍历语法树并作出优化,像是替换语法树中的变量,变成a,b,c那样的看不出意义的变量名。还有把 if/else 合并成三元运算符等。
最后输出代码的时候,全都输出成一行。
参考:
【Q137】js 代码压缩的原理是什么 · Issue #138 · shfshanyue/Daily-Question
播放器相关
有哪些常见的视频格式?
MP4、AVI、FLV、TS/M3U8、WebM、OGV、MOV...
有哪些常见的视频编码格式?
| H.264 | 目前最流行的编码格式。 |
| H.265 | 新型的编码格式,高效的视频编码。用来以替代 H.264/AVC 编码标准。 |
VP9 | VP9 是 WebM Project 开发的下一代视频编码格式 。VP9 支持从低比特率压缩到高质量超高清的所有 Web 和移动用例,并额外支持 10/12 位编码和 HDR |
| AV1 | AOM(Alliance for Open Media,开放媒体联盟)制定的一个开源、免版权费的视频编码格式。AV1 是 google 制定的 VP9 标准的继任者,也是 H265 强有力的竞争者。 |
各种流格式,以及他们的特点是什么
每一个你在网络上观看的视频或音频媒体都是依靠特定的网络协议进行数据传输,基本分布在会话层(Session Layer)、表示层(Presentation Layer)、应用层(Application Layer)。
常用协议:RTMP、RTP/RTCP/RTSP、HTTP-FLV、HLS、DASH。各个协议都有自己优势与劣势。

接下来对每一个进行详细介绍:
FLV
FLV 是 FLASH Video 的简称,FLV 流媒体格式是随着 Flash MX 的推出发展而来的视频格式。
在浏览器中 HTML5 的 <video> 是不支持直接播放 FLV 视频格式,需要借助 flv.js 这个开源库来实现播放 FLV 视频格式的功能。flv.js 是用纯 JavaScript 编写的 HTML5 Flash Video(FLV)播放器,它底层依赖于 Media Source Extensions。在实际运行过程中,它会自动解析 FLV 格式文件并喂给原生 HTML5 Video 标签播放音视频数据,使浏览器在不借助 Flash 的情况下播放 FLV 成为可能。
HLS
HLS(HTTP Live Streaming全称)是一个基于HTTP的视频流协议,由Apple公司实现,Mac OS上的QuickTime、Safari 以及iOS上的 Safari都能很好的支持 HLS,高版本 Android 也增加了对 HLS 的支持。其工作原理是服务端把整个流切分成一片片小的媒体流片段,客户端通过下载一个包含源数据的extended M3U(m3u8)playlist文件用于寻找可用的媒体流,随后开始下载格式为MPEG-TS的媒体片段。
一些常见的客户端如:MPlayerX、VLC 也都支持HLS协议,如果需要在chrome上播放,需要使用hls.js或者http-streaming
这里展示一个m3u8文件的例子:
#EXTM3U
#EXT-X-VERSION:3
#EXT-X-TARGETDURATION:17
#EXT-X-MEDIA-SEQUENCE:0
#EXT-X-KEY:METHOD=AES-128,URI="http://localhost:3000/key/encrypt.key",IV=0x00000000000000000000000000000000
#EXTINF:16.901411,
playlist0.ts
#EXTINF:4.563000,
playlist1.ts
#EXT-X-ENDLIST
RTMP
Real Time Messaging Protocol(简称 RTMP)是 Macromedia 开发的一套视频直播协议,现在属于 Adobe。这套方案需要搭建专门的 RTMP 流媒体服务如 Adobe Media Server,并且在浏览器中只能使用 Flash 实现播放器。它的实时性非常好,延迟很小,但无法支持移动端 WEB 播放是它的硬伤。
浏览器端,HTML5 video标签无法播放 RTMP 协议的视频,可以通过 video.js 来实现。
DASH
「基于 HTTP 的动态自适应流(英语:Dynamic Adaptive Streaming over HTTP,缩写 DASH,也称 MPEG-DASH)是一种自适应比特率流技术,使高质量流媒体可以通过传统的 HTTP 网络服务器以互联网传递。」 类似苹果公司的 HTTP Live Streaming(HLS)方案,MPEG-DASH 会将内容分解成一系列小型的基于 HTTP 的文件片段,每个片段包含很短长度的可播放内容,而内容总长度可能长达数小时。
不同于 HLS、HDS 和 Smooth Streaming,DASH 不关心编解码器,因此它可以接受任何编码格式编码的内容,如 H.265、H.264、VP9 等。
虽然 HTML5 不直接支持 MPEG-DASH,但是已有一些 MPEG-DASH 的 JavaScript 实现允许在网页浏览器中通过 HTML5 Media Source Extensions(MSE)使用 MPEG-DASH。另有其他 JavaScript 实现,如 bitdash 播放器支持使用 HTML5 加密媒体扩展播放有 DRM 的MPEG-DASH。当与 WebGL 结合使用,MPEG-DASH 基于 HTML5 的自适应比特率流还可实现 360° 视频的实时和按需的高效流式传输。
B站就是使用的这种视频格式:https://juejin.im/post/6844903968284360717
参考:
MSE是什么?如何使用MSE
媒体源扩展 API(MSE) 提供了实现无插件且基于 Web 的流媒体的功能。使用 MSE,媒体串流能够通过 JavaScript 创建,并且能通过使用 <audio> 和 <video> 元素进行播放。
MSE 使我们可以把通常的单个媒体文件的 src 值替换成引用 MediaSource 对象(一个包含即将播放的媒体文件的准备状态等信息的容器),以及引用多个 SourceBuffer 对象(代表多个组成整个串流的不同媒体块)的元素。MSE 让我们能够根据内容获取的大小和频率,或是内存占用详情(例如什么时候缓存被回收),进行更加精准地控制。 它是基于它可扩展的 API 建立自适应比特率流客户端(例如DASH 或 HLS 的客户端)的基础。
flv.js/hls.js/底层均基于此API完成对流媒体的兼容。
参考:
Media Source Extensions API - Web API 接口参考 | MDN
防盗链怎么做?
打个比方,引用一个视频mp4文件,直接在浏览器中打开却不起效果,必须挂着study.163.com域下才能成功。这就是防盗链。
原理:
http请求头部有一个表头字段叫referer,采用URL的格式来表示从哪儿链接到当前的网页或文件。
在服务器上设置白名单即可。
web视频怎么加密
我们先看看业界目前几个厂商怎么做的:
| 调研市场竞品视频加密情况汇总 | ||
|---|---|---|
| 视频点播网站 | 爱奇艺 | 缓存采用 HLS,文件格式 ts,可以获取地址直接播放,没有加密(包括 vip 视频) |
| 优酷 | 缓存采用 HLS,文件格式 ts,可以获取地址直接播放,没有加密视频文件 | |
| 短视频直播类 | 快手 | 回播视频采用 HLS,文件格式 ts,可以获取地址直接播放(ts 文件比较大,可以通过头 range 控制下载的 ts 文件大小),没有加密视频文件 |
| 抖音 | 视频是 mp4 格式,访问链接直接下载播放,没有对视频文件加密 | |
| 教育课程类 | 阿里学院 | 使用阿里云的私有加密方法(也是基于 HLS,替换了算法,必须基于阿里云播放器) |
| 腾讯课堂 | 采用 HLS 标准加密方法,可通过抓包获取密钥解密 ts 文件 | |
| 学而思网校 | 采用 HLS 标准加密方法,可通过抓包获取密钥解密 ts 文件 | |
可以看到基本都是基于HLS来加密。对HLS不了解可以参考各种流格式,以及他们的特点是什么。也有更加复杂的商业化加密方案,这里不讨论。
先看看一个简单的demo:FunnyLiu/video-hls-encrypt at readsource:

- 第一,把mp4的视频源通过
FFmpeg转换为加密后的m3u8文件和ts文件以及关键的加密密钥key文件; - 第二,通过最简单的权限访问,保护加密密钥key文件;
- 第三,利用
video.js及相关的videojs-contrib-hls.js实现客户端的视频文件解密,并播放。
再来看看商业级的完整方案及流程:
参考了阿里、腾讯云等厂商的标准 HLS 方案,大致思路基本相同。
整体架构分为 KMS、转码服务后台、鉴权与密钥派发服务、cdn、app 客户端和视频播放器 sdk
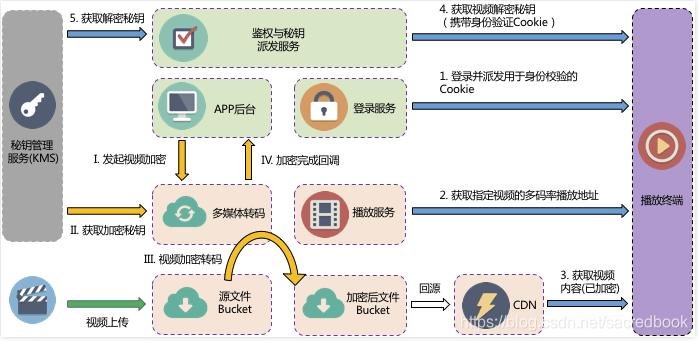
根据上图,总结加密流程:
1.app 后台发起视频加密服务,转码服务向 KMS 获取数据密钥(DK 和 EDK)和解密密钥获取 URL
名词解释:DK(由 KMS 系统生成的,用于对称加解密的密钥。实际用户加解密 ts 文件的)
EDK(任意用户都可以获取的,用来换 DK 的,DK 和 EDK 有对应关系,密钥服务可缓存这种关系,免去每次向 KMS 请求获取)
转码服务进行视频内容切片并使用密钥 DK 进行加密,在 M3U8 文件的 EXT-X-KEY 标签中会写入解密密钥的获取 URL 等信息。
发布加密后的 M3U8 视频播放地址
解密流程:
用户通过 app 登录,服务端会返回用户身份的 token
用户播放视频,访问 M3U8 下载对应的 ts 文件,通过 EXT-X-KEY 头中读取 URL,会向密钥服务请求解密密钥
https://getkey.example.com?fileId=123456&keySource=VodBuildInKMS&edk=abcdef&token=ABC123
如上例子所示,请求地址中保函 edk 和用户的 token,还有签名信息等,密钥服务会校验用户身份、签名等,通过后会根据资源 id 和 edk 返回解密 dk
- 播放器获得 DK,对 ts 文件进行解密,可以开始播放。
以上就是标准的 HLS 加解密的一个大致流程,这种方案对播放器没有限制,支持主流的大多数播放器。
这种加密最大的问题就是:
但是一个最大的问题就是(阿里云和腾讯云在官方文档都有说明),需要用户自己保护好 DK 密钥。因此 DK 传输到客户端之后的安全保障机制尤为关键。
按照标准的 HLS 加密方法,密钥 DK 一定会返回给客户端,因此通过在客户端进行劫持和抓包就能获取解密的 DK,故而视频 ts 文件就能轻松解密。
我爱破解、知乎上都有很多解密的拼接转码成完整视频 mp4 的教程和文章。
参考:
云点播视频-DRM-方案调研_sacredbook的博客-CSDN博客
云点播 HLS 普通加密 - 开发指南 - 文档中心 - 腾讯云
设计一个播放器框架
采用微内核架构。
参考源码分析



主要是基于插件和事件通信来完成所有功能的。是个典型的微内核架构。
通过eventEmitter来完成事件通信类,然后每个插件会拿到player的实例,在各个不同的事件抛出处进行事件通信。
整个播放器由各种不同的插件组成。
ui是基于dom操作/不依赖其他前端框架,来完成的。
插件又分为ui插件和逻辑插件,逻辑插件(packages/xgplayer/src/controls/.js)负责处理核心逻辑,ui插件(packages/xgplayer/src/skin/controls/.js)负责特定皮肤(默认皮肤)下的com和样式基本交互。
这里以播放按钮为例,逻辑插件为:
import Player from '../player'
let play = function () {
let player = this
//监听播放按钮点击视觉
function onPlayBtnClick () {
if (!player.config.allowPlayAfterEnded && player.ended) {
return
}
if (player.paused) {
let playPromise = player.play()
if (playPromise !== undefined && playPromise) {
playPromise.catch(err => {})
}
} else {
player.pause()
}
}
player.on('playBtnClick', onPlayBtnClick)
function onDestroy () {
player.off('playBtnClick', onPlayBtnClick)
player.off('destroy', onDestroy)
}
player.once('destroy', onDestroy)
}
export default {
name: 'play',
method: play
}
ui插件为:
import Player from '../../player'
import PlayIcon from '../assets/play.svg'
import PauseIcon from '../assets/pause.svg'
import '../style/controls/play.scss'
let s_play = function () {
let player = this
let util = Player.util
let playBtn = player.config.playBtn ? player.config.playBtn : {}
let btn
if (playBtn.type === 'img') {
btn = util.createImgBtn('play', playBtn.url.play, playBtn.width, playBtn.height)
} else {
btn = util.createDom('xg-play', `<xg-icon class="xgplayer-icon">
<div class="xgplayer-icon-play">${PlayIcon}</div>
<div class="xgplayer-icon-pause">${PauseIcon}</div>
</xg-icon>`, {}, 'xgplayer-play')
}
let tipsText = {}
tipsText.play = player.lang.PLAY_TIPS
tipsText.pause = player.lang.PAUSE_TIPS
let tips = util.createDom('xg-tips', `<span class="xgplayer-tip-play">${tipsText.play}</span>
<span class="xgplayer-tip-pause">${tipsText.pause}</span>`, {}, 'xgplayer-tips')
btn.appendChild(tips)
player.once('ready', () => {
if(player.controls) {
player.controls.appendChild(btn)
}
});
['click', 'touchend'].forEach(item => {
btn.addEventListener(item, function (e) {
e.preventDefault()
e.stopPropagation()
//基于事件触发
player.emit('playBtnClick')
})
})
}
export default {
name: 's_play',
method: s_play
}
参考:
前端进阶:跟着开源项目学习插件化架构 - SegmentFault 思否
有哪些常见的音频格式
音频格式也比较常见:WAV、AIFF、AMR、MP3、Ogg...
有哪些场景的音频编码格式
| PCM | 脉冲编码调制 (Pulse Code Modulation,PCM),PCM 是数字通信的编码方式之一。 |
| AAC-LC(MPEG AAC Low Complexity) | 低复杂度编码解码器(AAC-LC — 低复杂度高级音频编码)是低比特率、优质音频 的高性能音频编码解码器。 |
| AAC-LD | (又名 AAC 低延迟或 MPEG-4 低延迟音频编码器),为电话会议和 OTT 服务量身打造的低延迟音频编解码器 |
| LAC(Free Lossless Audio Codec) | 免费无损音频编解码器。是一套著名的自由音频压缩编码,其特点是无损压缩。2012 年以来它已被很多软件及硬件音频产品(如 CD 等)所支持。 |
多线程
webworker和主线程怎么通信?有什么局限性?
worker主线程:Web Worker可以分为两种不同线程类型,一个是专用线程,一个是共享线程。
使用限制:
Web Worker无法访问DOM节点;
Web Worker无法访问全局变量或是全局函数;
Web Worker无法调用alert()或者confirm之类的函数;
Web Worker无法访问window、document之类的浏览器全局变量;
//主线程代码
/** 1. 创建专用线程 **/
var worker = new Worker('dedicated.js');
/** 2. 接收来至工作线程 **/
worker.onmessage = function (event) { ... };
/** 3.发送 ArrayBuffer 数据代码 **/
worker.postMessage(10000);
/** 4.终止一个worker的执行 **/
worker.terminate();
------------------------------------------------
//worker线程代码
addEventListener("message", function(evt){
var date = new Date();
var currentDate = null;
do {
currentDate = new Date();
}while(currentDate - date < evt.data);
postMessage(currentDate);
}, false);
/** 1. 创建共享线程 **/
var worker = new SharedWorker('sharedworker.js', ’ mysharedworker ’ );
/** 2. 从端口接收数据 , 包括文本数据以及结构化数据 **/
worker.port.onmessage = function (event) { define your logic here... };
/** 3. 向端口发送普通文本数据 **/
worker.port.postMessage('put your message here … ');
/** 向端口发送结构化数据 **/
worker.port.postMessage({ username: 'usertext'; live_city:
['data-one', 'data-two', 'data-three','data-four']});
参考:
WEB前端面试题汇总(JS) - SegmentFault 思否
web worker有哪些应用场景?
Web Worker我们可以当做计算器来用,需要用的时候掏出来摁一摁,不用的时候一定要收起来~
加密数据
有些加解密的算法比较复杂,或者在加解密很多数据的时候,这会非常耗费计算资源,导致UI线程无响应,因此这是使用Web Worker的好时机,使用Worker线程可以让用户更加无缝的操作UI。
预取数据
有时候为了提升数据加载速度,可以提前使用Worker线程获取数据,因为Worker线程是可以是用 XMLHttpRequest 的。
预渲染
在某些渲染场景下,比如渲染复杂的canvas的时候需要计算的效果比如反射、折射、光影、材料等,这些计算的逻辑可以使用Worker线程来执行,也可以使用多个Worker线程,这里有个射线追踪的示例。
复杂数据处理场景
某些检索、排序、过滤、分析会非常耗费时间,这时可以使用Web Worker来进行,不占用主线程。
预加载图片
有时候一个页面有很多图片,或者有几个很大的图片的时候,如果业务限制不考虑懒加载,也可以使用Web Worker来加载图片,可以参考一下这篇文章的探索,这里简单提要一下。
参考:
webworker应用场景_Web Workers 的使用场景有哪些_杨明月luna的博客-CSDN博客
本地存储
localStoarge、sessionStorage、CacheStorage有什么区别?
HTML5的WebStorage提供了两种API:localStorage(本地存储)和sessionStorage(会话存储)。
1、生命周期:localStorage:localStorage的生命周期是永久的,关闭页面或浏览器之后localStorage中的数据也不会消失。localStorage除非主动删除数据,否则数据永远不会消失。
sessionStorage的生命周期是在仅在当前会话下有效。sessionStorage引入了一个“浏览器窗口”的概念,sessionStorage是在同源的窗口中始终存在的数据。只要这个浏览器窗口没有关闭,即使刷新页面或者进入同源另一个页面,数据依然存在。但是sessionStorage在关闭了浏览器窗口后就会被销毁。同时独立的打开同一个窗口同一个页面,sessionStorage也是不一样的。
2、存储大小:localStorage和sessionStorage的存储数据大小一般都是:5MB
3、存储位置:localStorage和sessionStorage都保存在客户端,不与服务器进行交互通信。
4、存储内容类型:localStorage和sessionStorage只能存储字符串类型,对于复杂的对象可以使用ECMAScript提供的JSON对象的stringify和parse来处理
5、获取方式:localStorage:window.localStorage;;sessionStorage:window.sessionStorage;。
6、应用场景:localStoragese:常用于长期登录(+判断用户是否已登录),适合长期保存在本地的数据。sessionStorage:敏感账号一次性登录;
CacheStorage 接口表示 Cache 对象的存储。它提供了一个 ServiceWorker 、其它类型worker或者 window 范围内可以访问到的所有命名cache的主目录(它并不是一定要和service workers一起使用,即使它是在service workers规范中定义的),并维护一份字符串名称到相应 Cache 对象的映射。
localstorage怎么实现跨域通信?
通过iframe一个中间页,这个中间页来做所有的localStorage,再postmessage通信给其他域名来完成。
参考:
IndexedDB简单介绍下
ndexedDB就是一个非关系型数据库,它不需要你去写一些特定的sql语句来对数据库进行操作,因为它是nosql的,数据形式使用的是json。
IndexedDB很适合存储大量数据,它的API是异步调用的。IndexedDB使用索引存储数据,各种数据库操作放在事务中执行。IndexedDB甚至还支持简单的数据类型。IndexedDB比localstorage强大得多,但它的API也相对复杂。对于简单的数据,你应该继续使用localstorage,但当你希望存储大量数据时,IndexedDB会明显的更适合,IndexedDB能提供你更为复杂的查询数据的方式。
参考:
IndexedDB有哪些特点?
IndexedDB 具有以下特点。
(1)键值对储存。 IndexedDB 内部采用对象仓库(object store)存放数据。所有类型的数据都可以直接存入,包括 JavaScript 对象。对象仓库中,数据以"键值对"的形式保存,每一个数据记录都有对应的主键,主键是独一无二的,不能有重复,否则会抛出一个错误。
(2)异步。 IndexedDB 操作时不会锁死浏览器,用户依然可以进行其他操作,这与 LocalStorage 形成对比,后者的操作是同步的。异步设计是为了防止大量数据的读写,拖慢网页的表现。
(3)支持事务。 IndexedDB 支持事务(transaction),这意味着一系列操作步骤之中,只要有一步失败,整个事务就都取消,数据库回滚到事务发生之前的状态,不存在只改写一部分数据的情况。
(4)同源限制 IndexedDB 受到同源限制,每一个数据库对应创建它的域名。网页只能访问自身域名下的数据库,而不能访问跨域的数据库。
(5)储存空间大 IndexedDB 的储存空间比 LocalStorage 大得多,一般来说不少于 250MB,甚至没有上限。
(6)支持二进制储存。 IndexedDB 不仅可以储存字符串,还可以储存二进制数据(ArrayBuffer 对象和 Blob 对象)。
参考:
浏览器数据库 IndexedDB 入门教程 - 阮一峰的网络日志
IndexedDB的接口为什么是异步的?
IndexedDB 操作时不会锁死浏览器,用户依然可以进行其他操作,这与 LocalStorage 形成对比,后者的操作是同步的。异步设计是为了防止大量数据的读写,拖慢网页的表现。
参考:
浏览器数据库 IndexedDB 入门教程 - 阮一峰的网络日志
CacheStorage
前端缓存有哪些
localstoarge、sessionstorage、CacheStorage from memory cache 和 from disk cache dns缓存 http缓存
国际化
怎么做国际化?
国际化分为静态和动态,静态就是前端文案,动态是后端返回的。
一、通过i18等插件,在项目代码中定义语言环境,通过通用的语言翻译函数,提供的功能就是静态和动态文案的翻译。主要思路就是通过构建工具去完成样式, 图片替换, class属性等的替换工作,在业务代码中不会出现过多的因国际化而多出的变量名,同时使用一个通用的翻译函数去完成静态文案及动态文案的翻译工作,而不用使用不同框架提供的相应的国际化插件。
二、在项目中不使用插件,而是封装一套通用的翻译函数,在后台服务那边定义语言环境,通过API服务调用不同的主题和语言环境,返回不同的字段和页面内容。(项目代码中无中文,全是用翻译函数包裹后的变量)
也可以使用web翻译平台,产出语言包。比如weblate这种。
低代码
一般的低代码平台需要具备哪些能力?
阿里的imgCook、云凤蝶、京东的通天塔、满帮的码良、徐小夕的H5 Doring等等,无一例外,至少都满足一下几种能力:
1、面向业务的软件设计模式,低代码主要是给运营用的,通过模块or组件的使用,给运营人员提供物料,搭建他们自己想要的营销活动页面。
2、能够提供可复用业务组件的知识库,组件之间可以相互联合,组成新的业务组件,而不是单一独立的基础组件,可复用性、可拓展性非常高。
3、能够方便实现与第三方系统整合的流程整合能力与数据整合能力等,能够以SDK,或者npm包的形式嵌入到其他应用,或者其他应用嵌入进来,支持数据之间的整合。
4、能够支持多种部署模式,不受平台本身的限制
5、支持高度可配置化,以满足不同环境、不同规模、不同业务场景的特定要求